Introduction
Neural Network is a type of computational model that is inspired by the human brain, in which the neurons are organized in layers and the neurons in different layer are interconnected. Neural networks has many application in autonomous driving, natural language processing and image/speech recognition. In this technical blog, I will discuss CUDA implementation of one forward and backward propagation of a three-layer neural network, in which the result of the CUDA implementation was compared with Pytorch implementation. The comparison with Pytorch implementation helps with debugging since Pytorch has been well tested by the deep learning development community. The Pytorch initialized weights and biases are used in CUDA implementation because it easier for comparison between Pytorch and CUDA implementation. This blog experimented with allocating one memory for the weights and biases of a layer however the storage will be restricted to column major for efficient memory bandwith. This technical blog is intended to document my understanding on how neural network works and its CUDA implementation. Additionally, the kernel functions used in this blog were not optimized. I discussed kernel optimization in this blog and also there is a lot of optimization opportunities for all the kernel functions used here.
Forward Propagation
Forward propagation is a process where the neural network takes an input to produce an output or prediction. In the three layer neural network, the two hidden layer has a ReLu(Rectified Linear Unit) activation and output layer has a sigmoid activation function.
Forward propagation steps in a three layer neural network(The steps with the same color happen in the same layer).

First Layer (First step).
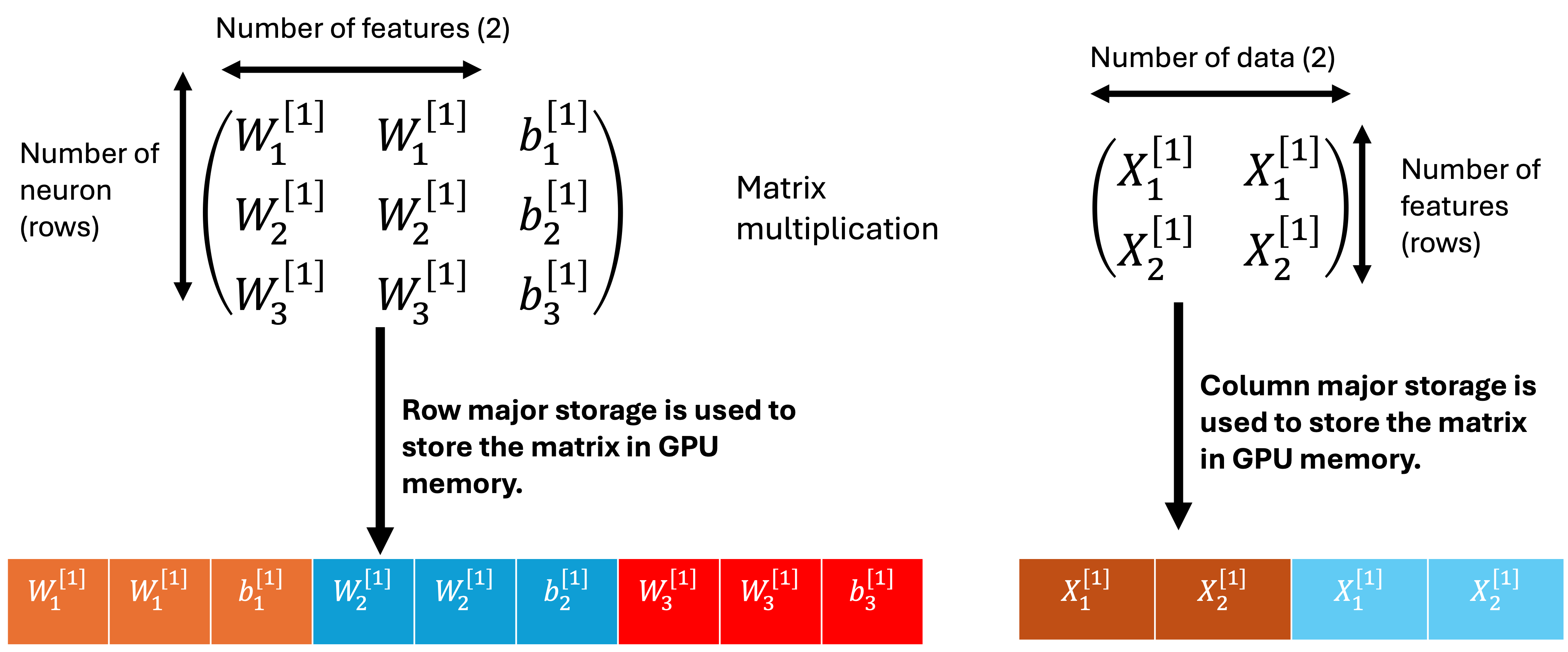
The first step involves matrix multiplication between First layer weights and input data and then the addition of the First Layer bias. Row major storage is used to weight and bias in GPU memory while column major storage is used to store the input data in GPU memory. The column major storage is used to store the matrix mutiplication product in GPU memory. The first step result is left in the GPU memory to be used by the second step.
matrix representation of the first step
// kernel function for the first step
__global__ void matrixMulAddRowBasedARR2(float* weightBias, float* xData, float* activationValues, int wRows, int xCols, int wColsXRows) {
int gid = blockIdx.x * blockDim.x + threadIdx.x;
if (gid < (wRows * xCols)) {
int index = gid / wRows;
int indexR = gid - (index * wRows);
int indexW = index * (wColsXRows);
int indexMul = indexR * (wColsXRows+1);
float sum = 0.0;
for (int i = 0; i < wColsXRows; i++) {
sum+=(weightBias[i+indexMul] * xData[i+indexW]);
}
sum+=weightBias[indexMul+wColsXRows];
activationValues[gid] = sum;
}
}
First layer (second step).
The second step involves applying the ReLu function on the product of the first step.
matrix representation of the second step.

// kernel function for the second step
__global__ void matrixReLu(float* activation, int actLength) {
int gid = blockIdx.x * blockDim.x + threadIdx.x;
if (gid < actLength) {
activation[gid] = (activation[gid] > 0.0) ? activation[gid] : 0.0;
}
}
Second layer (Third step).
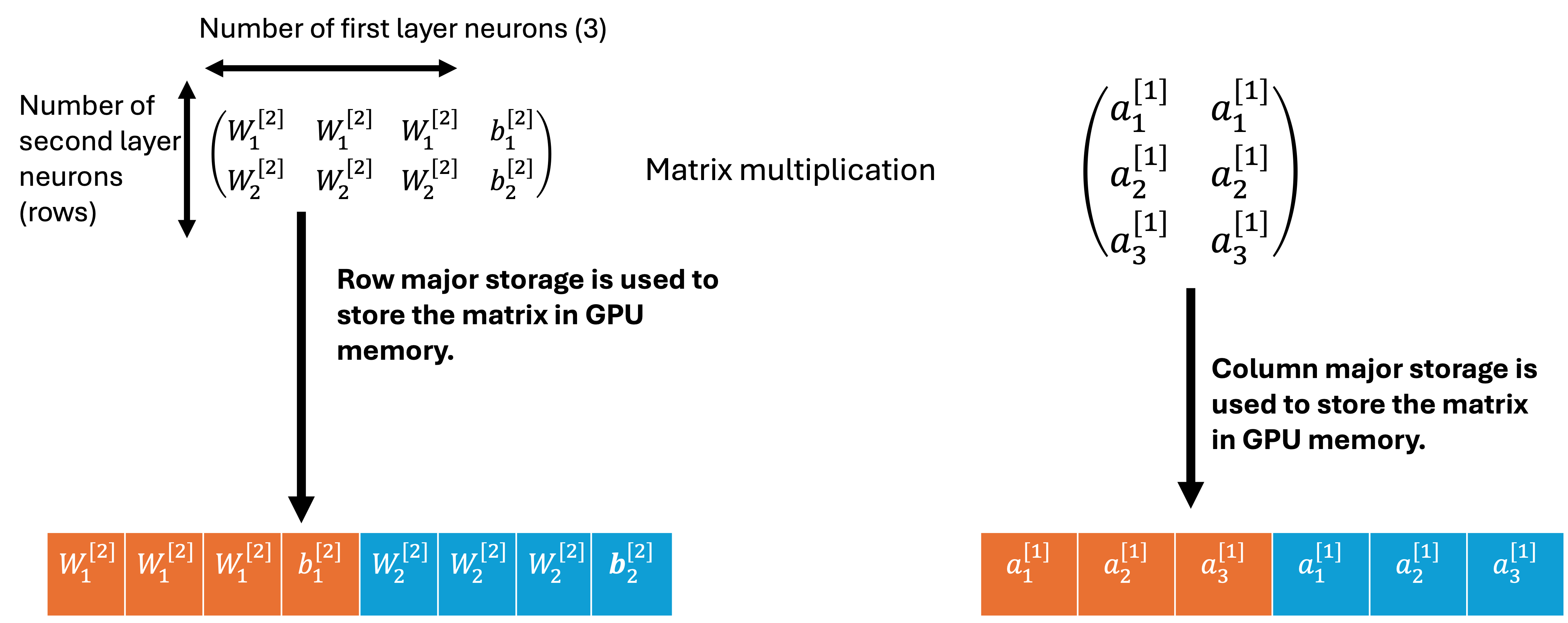
Third step operation is the same as the first step but it involves matrix mutiplication of second layer weights with the output of layer one (second step) and then addition of the second layer bias. The third step uses the same kernel function as the first step.
matrix representation of the third step.
Second layer (four step).
Fourth step operation is the same as the second step, in which ReLu function is applied on the third step result. The fourth step uses the same kernel function as second step.
matrix representation of the fourth step.
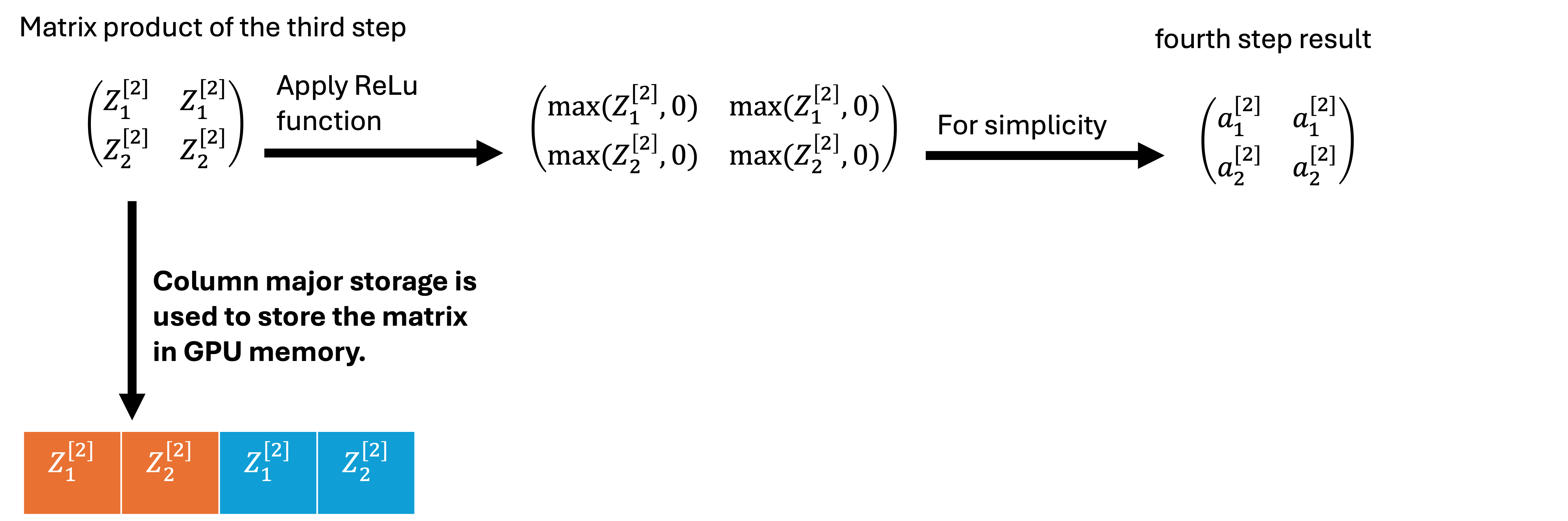
Third layer (fifth step).
Fifth step operation is the same as the first step but it involves matrix mutiplication of third layer weights with output layer two(fourth step) and then addition of the third layer bias. The fifth step uses different kernel function since the output is row major storage. The last layer must have a single neuron since the code is structured for only binary classification. In the future, the code will be updated to multiclass classification with softmax.
matrix representation of the fifth step.

__global__ void matrixMulAddRowBasedARR(float* weightBias, float* xData, float* activationValues, int wRows, int xCols, int wColsXRows) {
int gid = blockIdx.x * blockDim.x + threadIdx.x;
if (gid < (wRows * xCols)) {
int index = gid / xCols;
int indexR = gid - (index * xCols);
int indexW = index * (wColsXRows+1);
int IndexMul = indexR * wColsXRows;
float sum = 0.0;
for (int i = 0; i < wColsXRows; i++) {
sum+=(weightBias[i+indexW] * xData[i+IndexMul]);
}
sum+=weightBias[indexW+wColsXRows];
activationValues[index+(indexR*wRows)] = sum;
}
}
Third layer (sixth step).
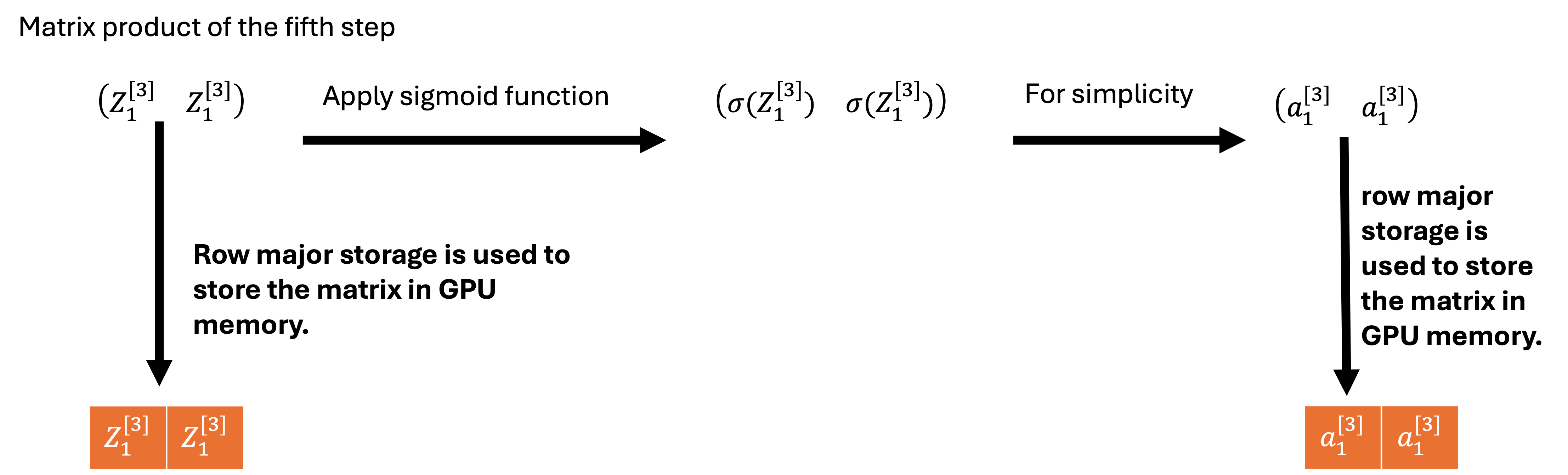
The sixth step involves applying the sigmoid function on the product of the fifth step.
matrix representation of the sixth step.
// Kernel function for the sixth step
__global__ void matrixSigmoid(float* activation, int actLength) {
int gid = blockIdx.x * blockDim.x + threadIdx.x;
if (gid < actLength) {
activation[gid] = 1/(1 + exp(-activation[gid]));
}
}
Backward propagation.
Backward propagation involves changing the weight and biases through the network in other to minimize the error. The backward propagation is more computationally complex than the forward propagation because it involves calculation of the gradient of the weights and biases by applying chain rules backward through the neural network. In this technical blog, the cuda implementation of the backward propagation was simplified by starting from the sixth step.
Sixth step
The sixth step involves substracting the actual data from the predicted data (dL/dZ3).
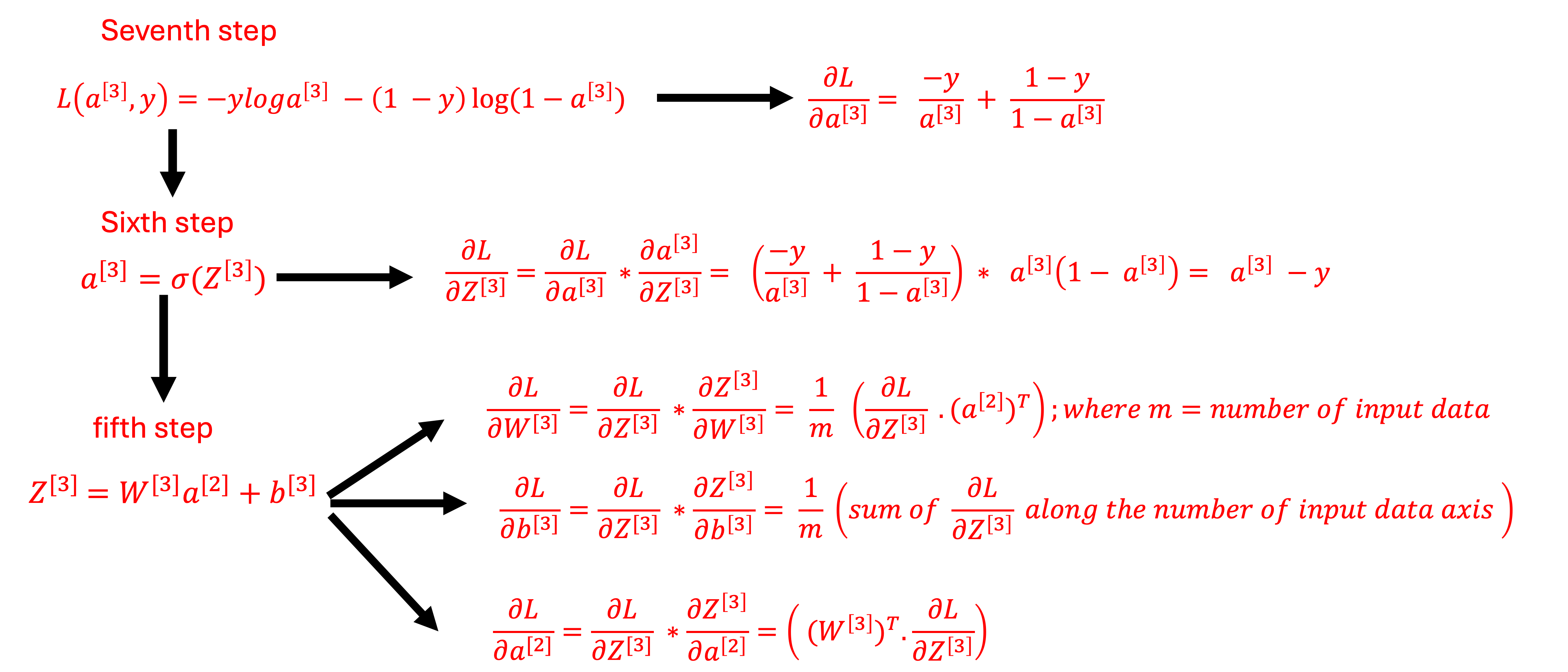
// kernel function for the sixth step
__global__ void elementWiseSub(float* firstArray, float* secondArray, int arraySize) {
int gid = blockIdx.x * blockDim.x + threadIdx.x;
if (gid < (arraySize)) {
firstArray[gid]=firstArray[gid] - secondArray[gid];
}
}
Fifth step
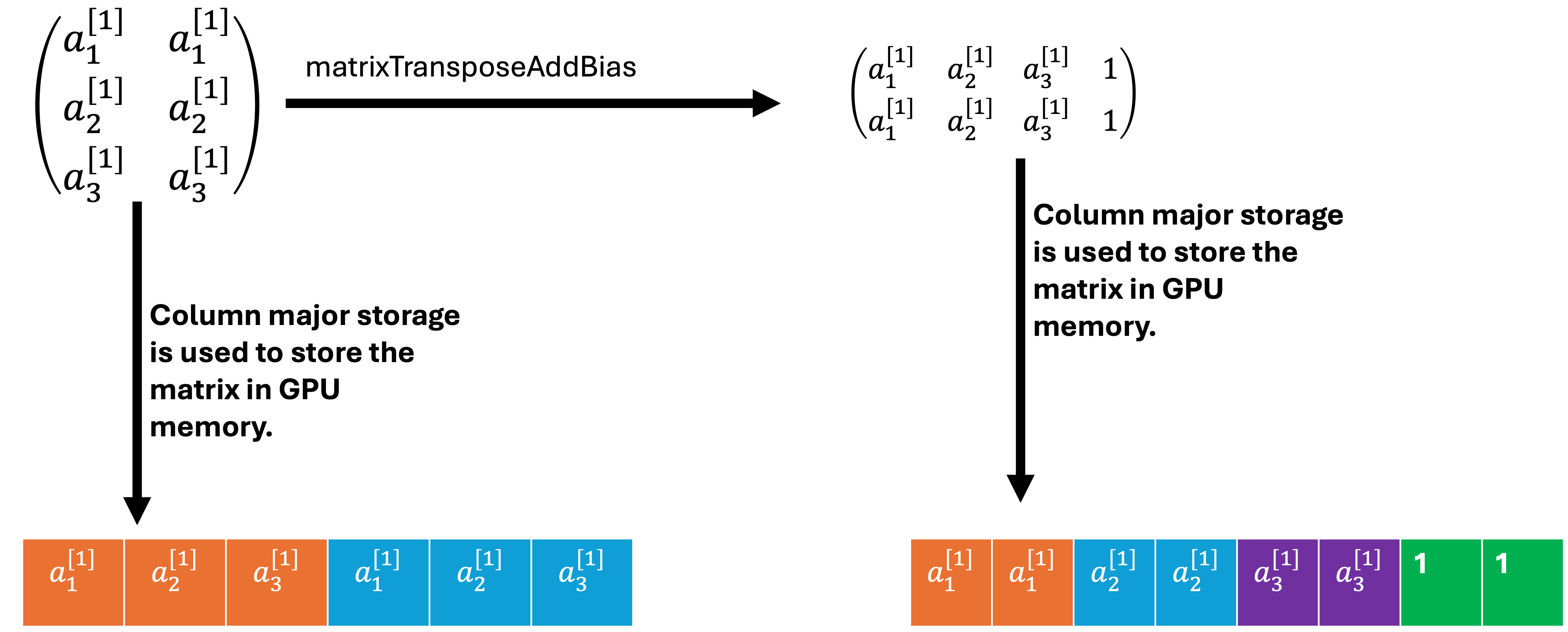
The fifth step requires calculating the derivatives of the loss function with respect to W3, b3 and a2. The dL/dZ3 is multiplied with the transpose of a2 to get dW3 and db3. Please note, an extra column (filled up with 1) was added to a2 in the matrixTransposeAddBias function. This will require allocating extra GPU memory for a2, which is the size of one column of a2. Therefore, in the future, matrixdL_dW3 function will be updated so that extra GPU memory will not be allocated for a2. Transpose of W3 is multiplied with dL/dZ3 to get dL/da2.
// kernel function used for transpose a2 from column major storage to row major storage.
// kernel function add one extra rows that is filled with one b/cos it used to calculate dL/db3 since W and b is in the same matrix
__global__ void matrixTransposeAddBias(float* matrixArray, float* matrixArrayTranspose, int nrows, int ncols) {
int gid = blockIdx.x * blockDim.x + threadIdx.x;
int index = gid / ncols;
int indexR = gid - (index * ncols);
if (gid < (nrows*(ncols+1))) {
if (gid < (nrows*ncols)) {
matrixArrayTranspose[index+(indexR*nrows)] = matrixArray[gid];
} else {
matrixArrayTranspose[gid] = 1.0;
}
}
}
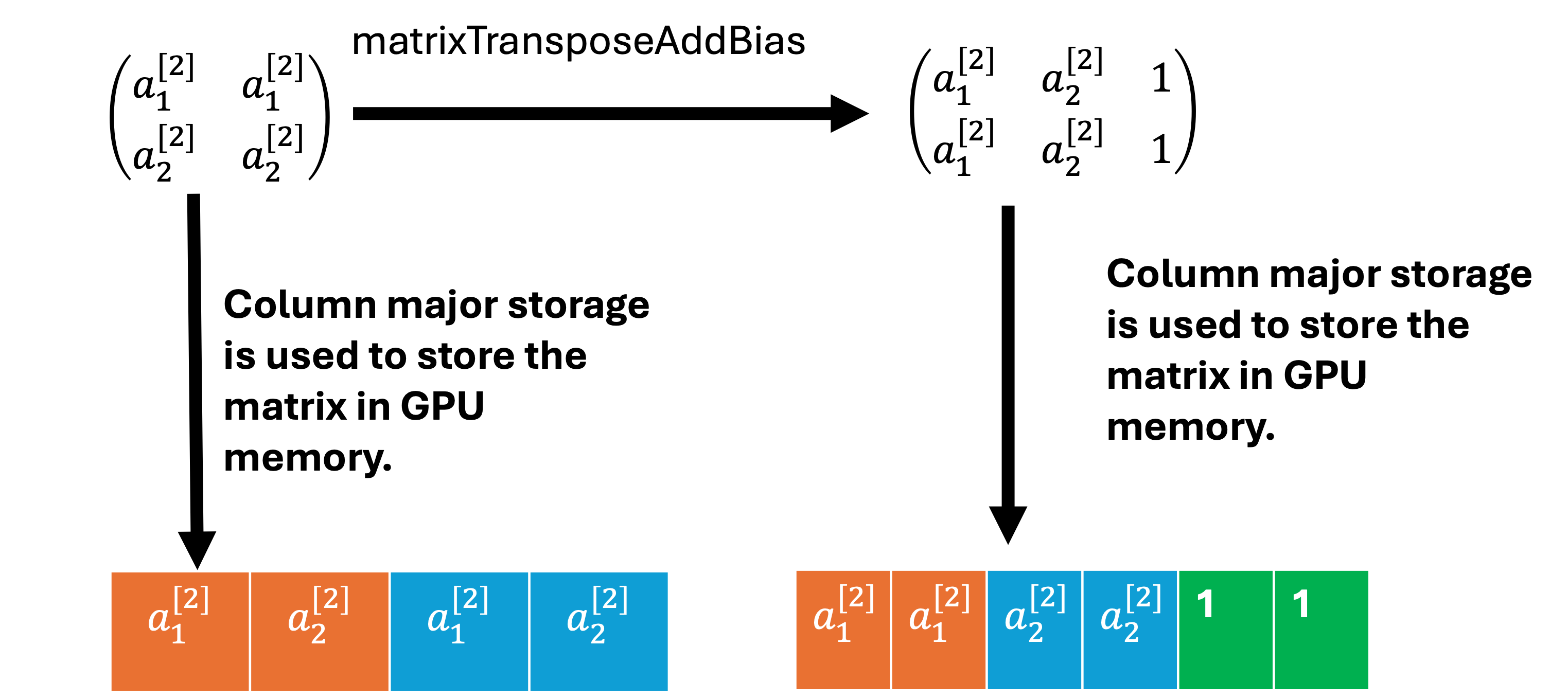
// kernel function for calculation of dL/dW3 and dL/db3
__global__ void matrixdL_dW3(float* weightBias, float* xData, float* activationValues, int wRows, int xCols, int wColsXRows) {
int gid = blockIdx.x * blockDim.x + threadIdx.x;
if (gid < (wRows * xCols)) {
int index = gid / xCols;
int indexW = index * (wColsXRows);
int indexStart = gid % xCols;
int IndexMul = indexStart * wColsXRows;
float sum = 0.0;
for (int i = 0; i < wColsXRows; i++) {
sum+=(weightBias[i+indexW] * xData[i+IndexMul]);
}
activationValues[gid] = sum/float(wColsXRows);
}
}

// kernel function is used to update the weight and biases with adam optimizer
__global__ void AdamOptUpdate(float* weightBias, float* dL_dW3, int len, float lr, float beta1, float beta2, float epsilon, float* mt, float* vt) {
int gid = blockIdx.x * blockDim.x + threadIdx.x;
if (gid < len) {
mt[gid] = (beta1*mt[gid]) + (1 - beta1)*dL_dW3[gid];
vt[gid] = (beta2*vt[gid]) + (1 - beta2)*(powf(dL_dW3[gid], 2.0));
float mt_crt = mt[gid]/(1-beta1);
float vt_crt = vt[gid]/(1-beta2);
weightBias[gid] = weightBias[gid] - ((mt_crt/(sqrt(vt_crt + epsilon)))*lr);
}
}
// kernel function is used to calculate dL/da2 from the matrix multiplication of W3 Transpose with dL/dZ3
__global__ void matrixMultRow(float* weightBias, float* xData, float* activationValues, int wRows, int xCols, int wColsXRows) {
int gid = blockIdx.x * blockDim.x + threadIdx.x;
if (gid < (wRows * xCols)) {
int index = gid / xCols;
int indexW = index * (wColsXRows);
int indexStart = gid % xCols;
int IndexMul = indexStart * wColsXRows;
float sum = 0.0;
for (int i = 0; i < wColsXRows; i++) {
sum+=(weightBias[i+indexW] * xData[i+IndexMul]);
}
activationValues[gid] = sum;
}
}
Fourth step
The derivative of the ReLu(x) is one if ReLu(x) is x and zero if ReLu(x) is 0. The fourth step is the elementwise multiplication of the derivative of ReLu(Z2) with dL/da2 to get dL/dZ2.
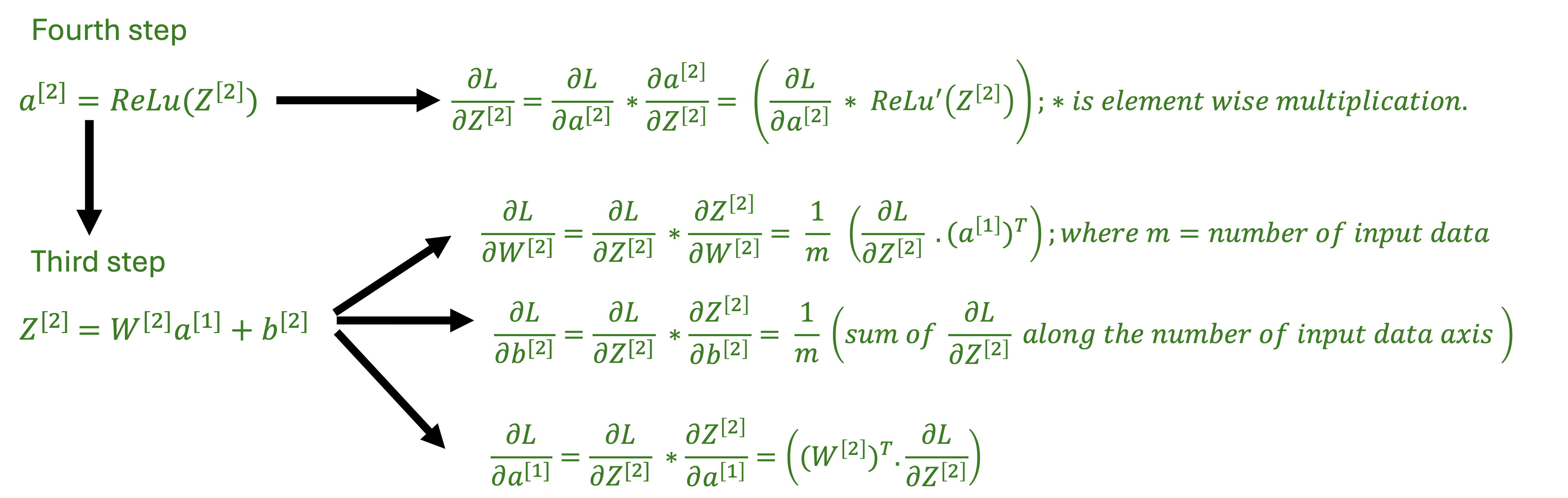
// kernel function for the derivative of the ReLu function
__global__ void matrixDiffReLu(float* activation, int actLength) {
int gid = blockIdx.x * blockDim.x + threadIdx.x;
if (gid < actLength) {
activation[gid] = (activation[gid] > 0.0) ? 1.0 : 0.0;
}
}
// kernel function for the elementwise multiplication of dL/da2 * ReLu'(Z2]
__global__ void elementWiseMult(float* firstArray, float* secondArray, float* outputArray, int arraySize) {
int gid = blockIdx.x * blockDim.x + threadIdx.x;
if (gid < (arraySize)) {
outputArray[gid]=firstArray[gid] * secondArray[gid];
}
}
Third step
The third step is the same as the fifth step but it is for the derivatives of the loss function with respect to W2, b2 and a1. The dL/dZ2 is multiplied with the transpose of a1 to get dW2 and db2. Transpose of W2 is multiplied with dL/dZ2 to get dL/da1. Third step uses the same kernel function as the fifth step.

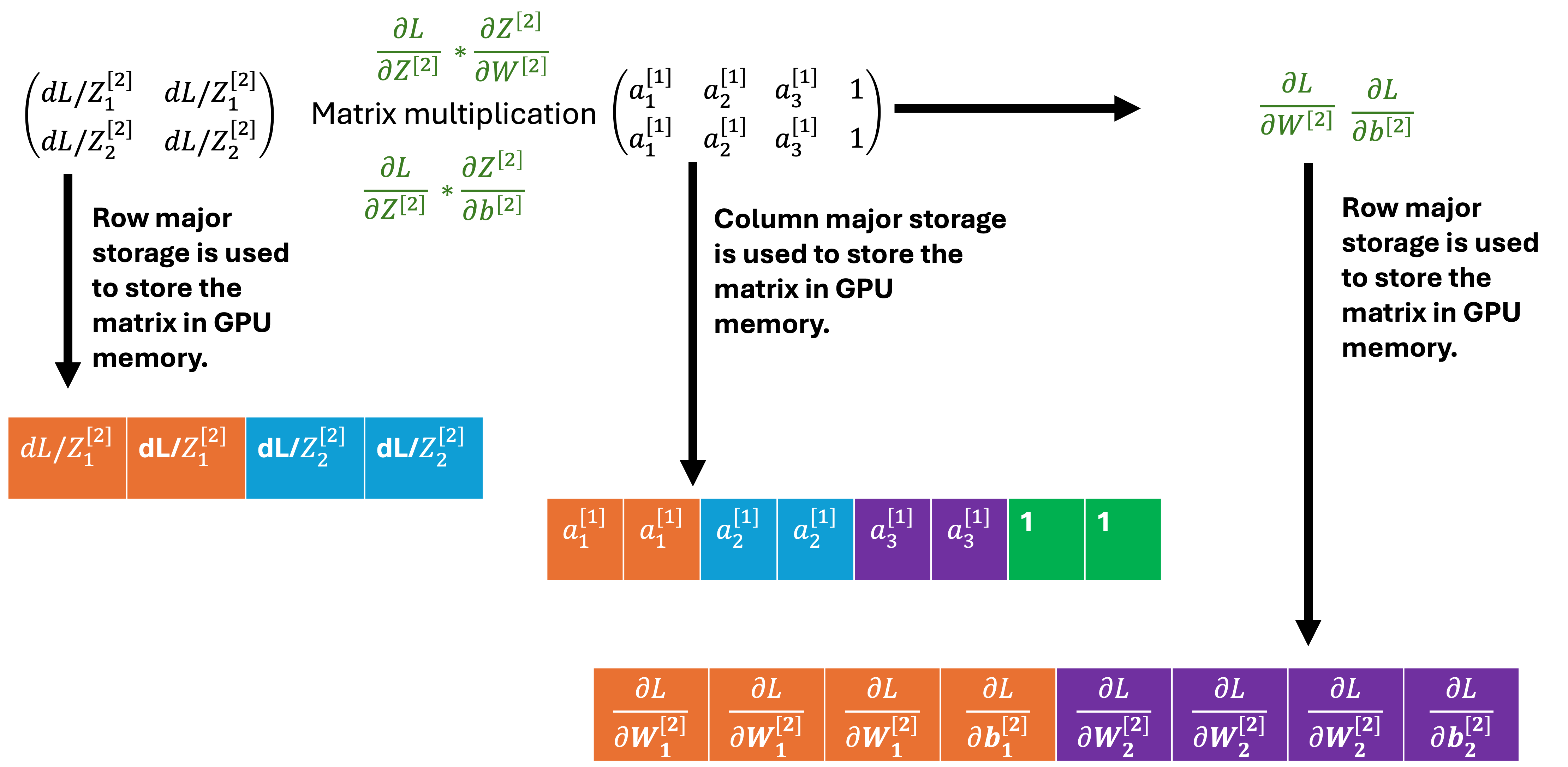
Second step
The second step is similar to the fourth step but it is the is the elementwise multiplication of the derivative of ReLu(Z1) with dL/da1 to get dL/dZ1.
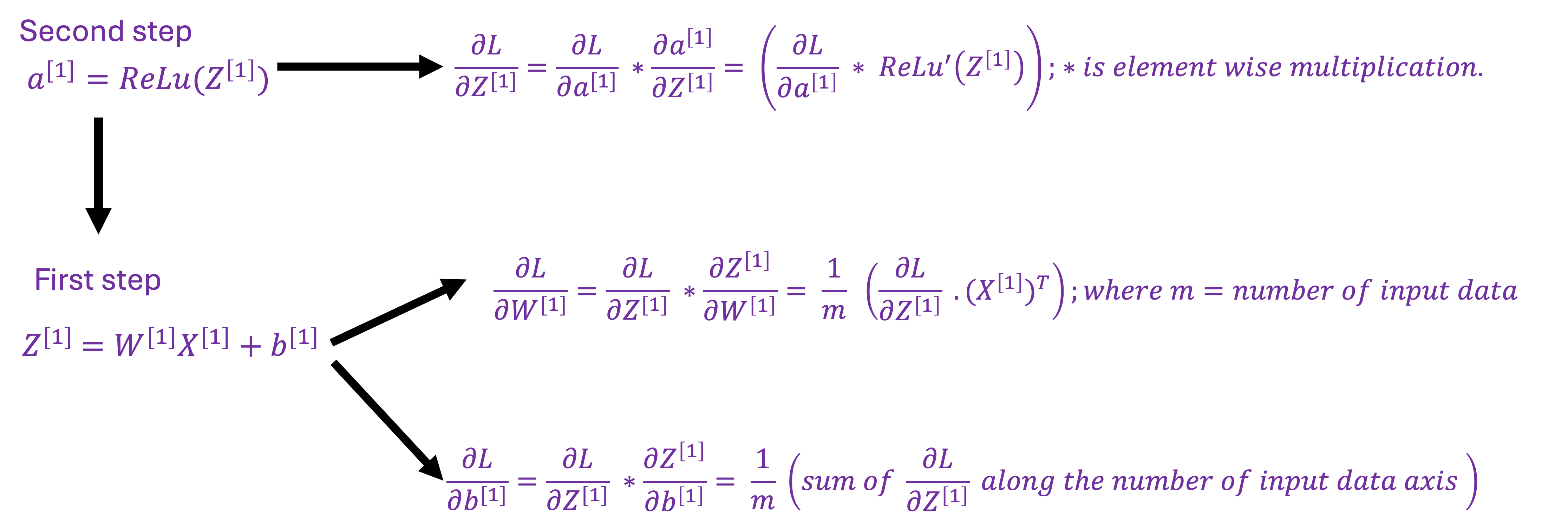
First step
The first step is the similar to the third step but it is for the derivatives of the loss function with respect to W1 and b1.
Conclusion
This techical blog discussed step by step CUDA implementation of a one forward and backpropagation of a three layer neural network and compared results with Pytorch. All my code is available on Github.