Introduction.
Euclidean matrix distance is an nxn matrix representing the euclidean distance between set of n points in Euclidean space. Euclidean distance matrix has so many application in machine learning, Engineering and robotics and image processing. This technical blog will discuss step by step on how to optimize CUDA kernel for Euclidean Distance Matrix for 2D coordinate points. The equation for calculating the euclidean distance distance between {x1, y1} and {x2, y2}:
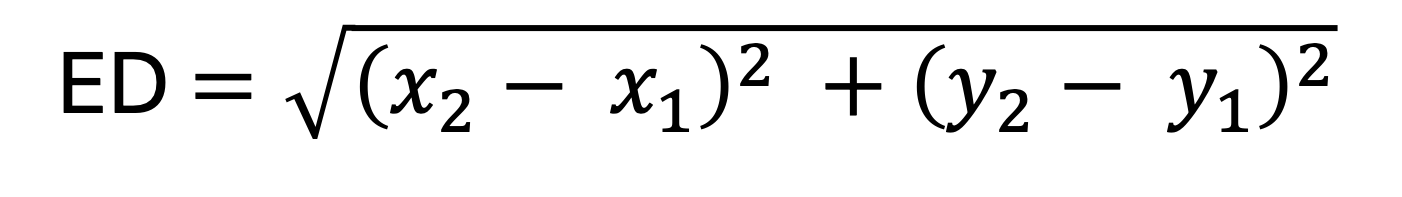
Memory bound vs Compute bound for Euclidean distance Matrix.
The eucildean distance calculation between 2D cooordinate points involves two substraction, two multiplication, one addition and one sqrt. According to this post, sqrt() function involves about four to five floating point operation. Therefore, one euclidean distance calculation between 2D coordinates points involves 9 floating point operation. For 30336 2D coordinate points, which is what was used in this optimization.
- Total FLOPS: 303362 * 9 FLOPS = 8282456064B(8.28GFLOPS).
- Minimum total data to read: 30336 * 8B = 242688B(242KB).
- Total data to write: 303362 * 4B = 3681091584B(3.68GB).
The Nvidia RTX 5070 Ti has a memory bandwith of 896GB/sec and has a fp32 compute throughput of 41TFLOPS. Therefore, the theoretical time for the calculation is 0.2 milliseconds while the theoretical total time for data read and write is 4.1 milliseconds assuming the both total read and write is 3.68GB. This simple theoretical calculation shows that the euclidean distance matrix calculation is memory-bound.
Kernel 1: Naive implementation.
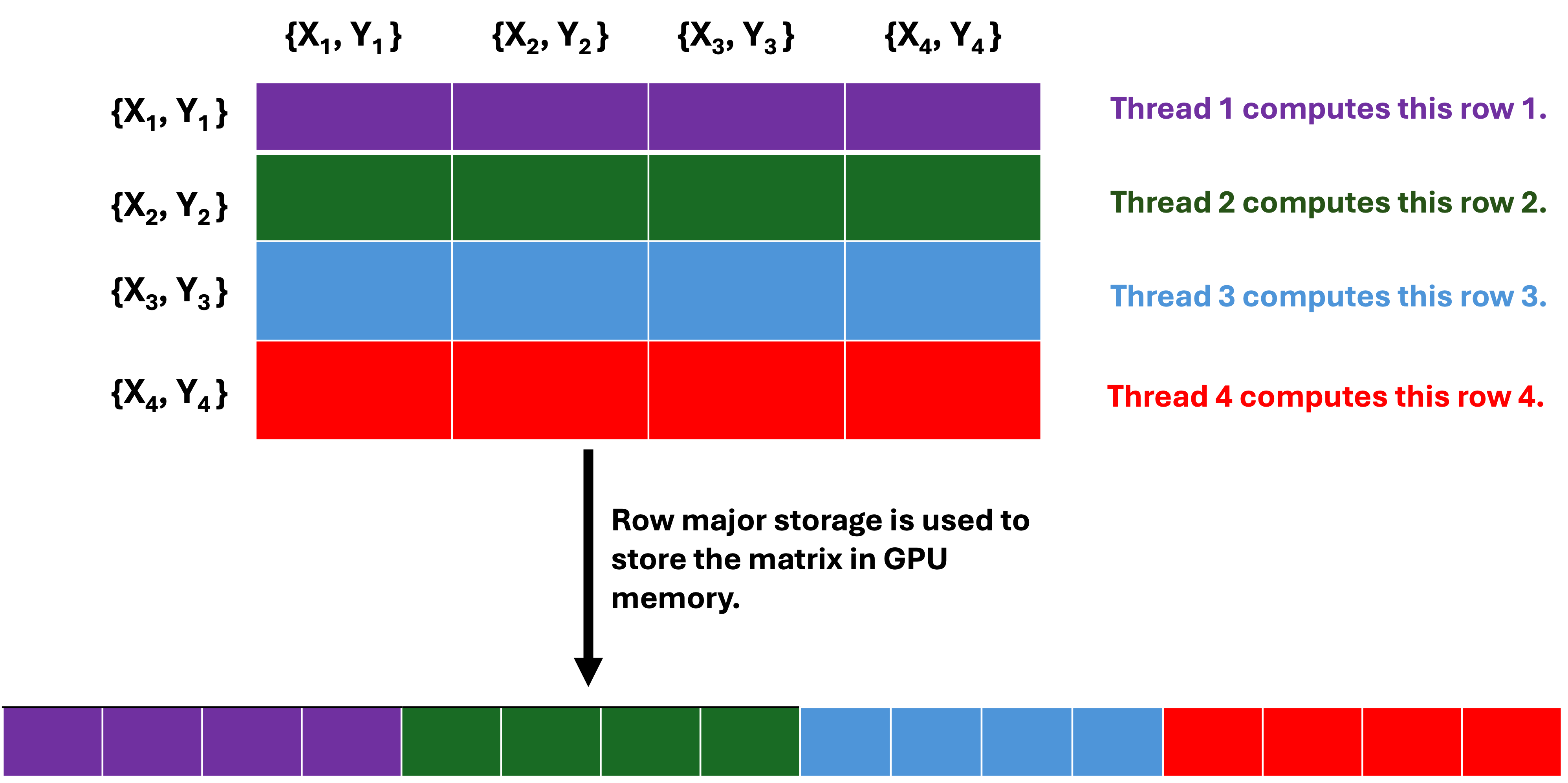
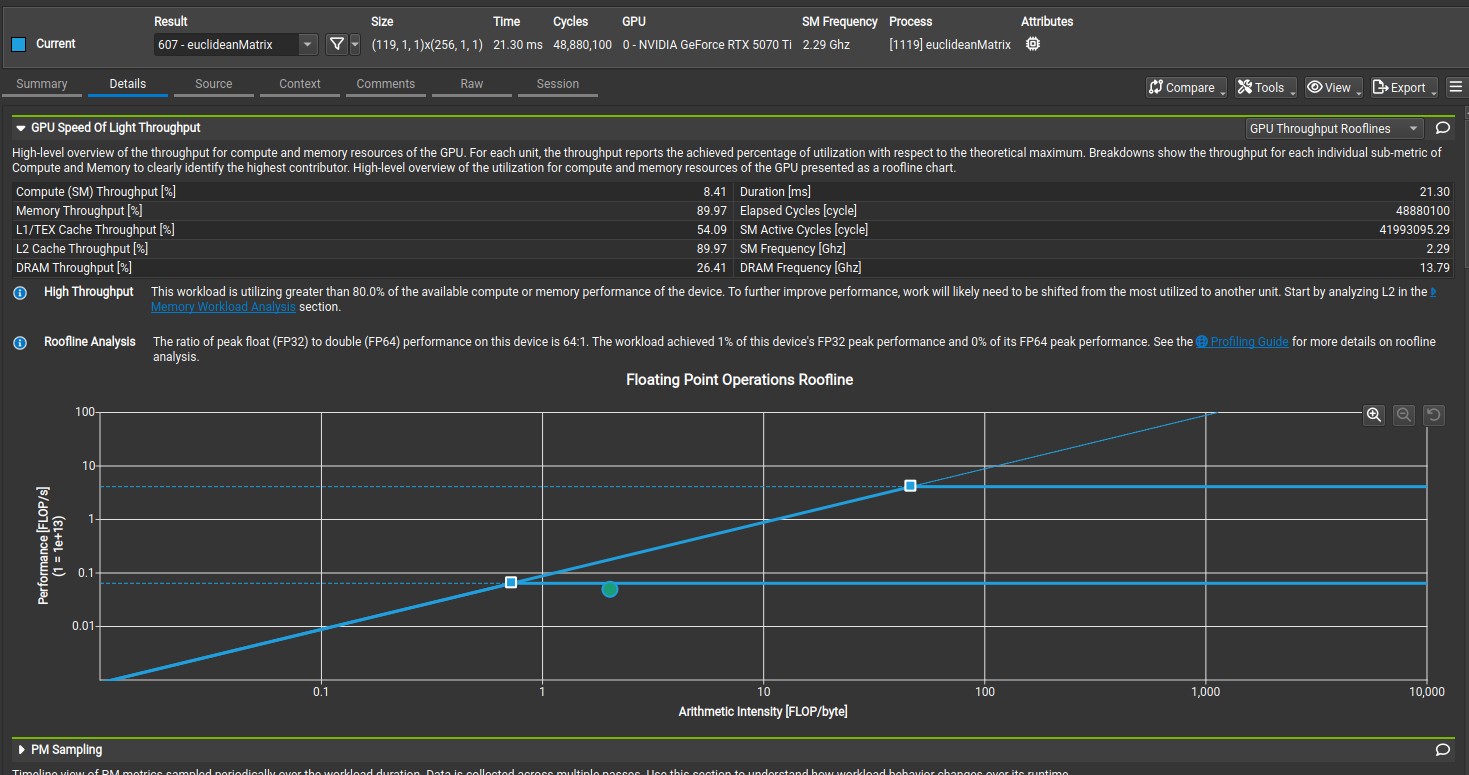
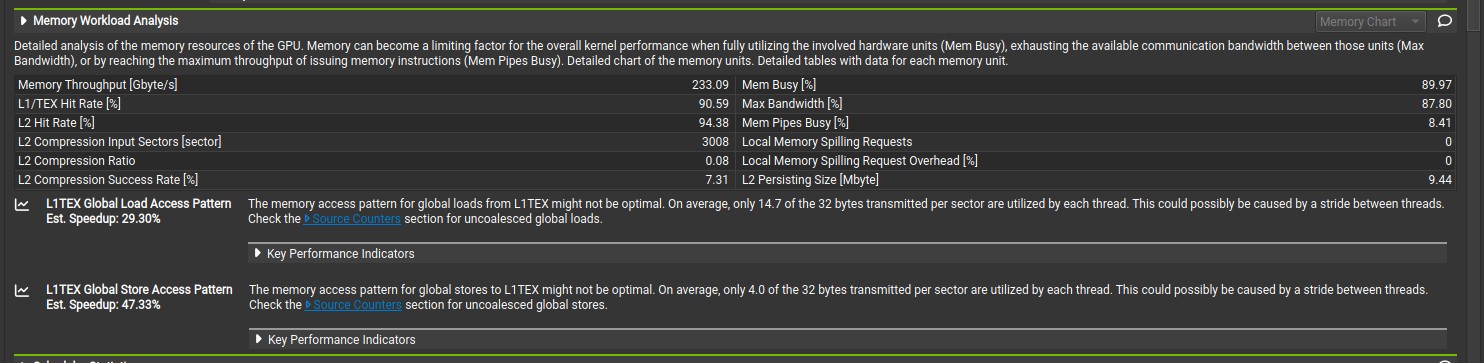
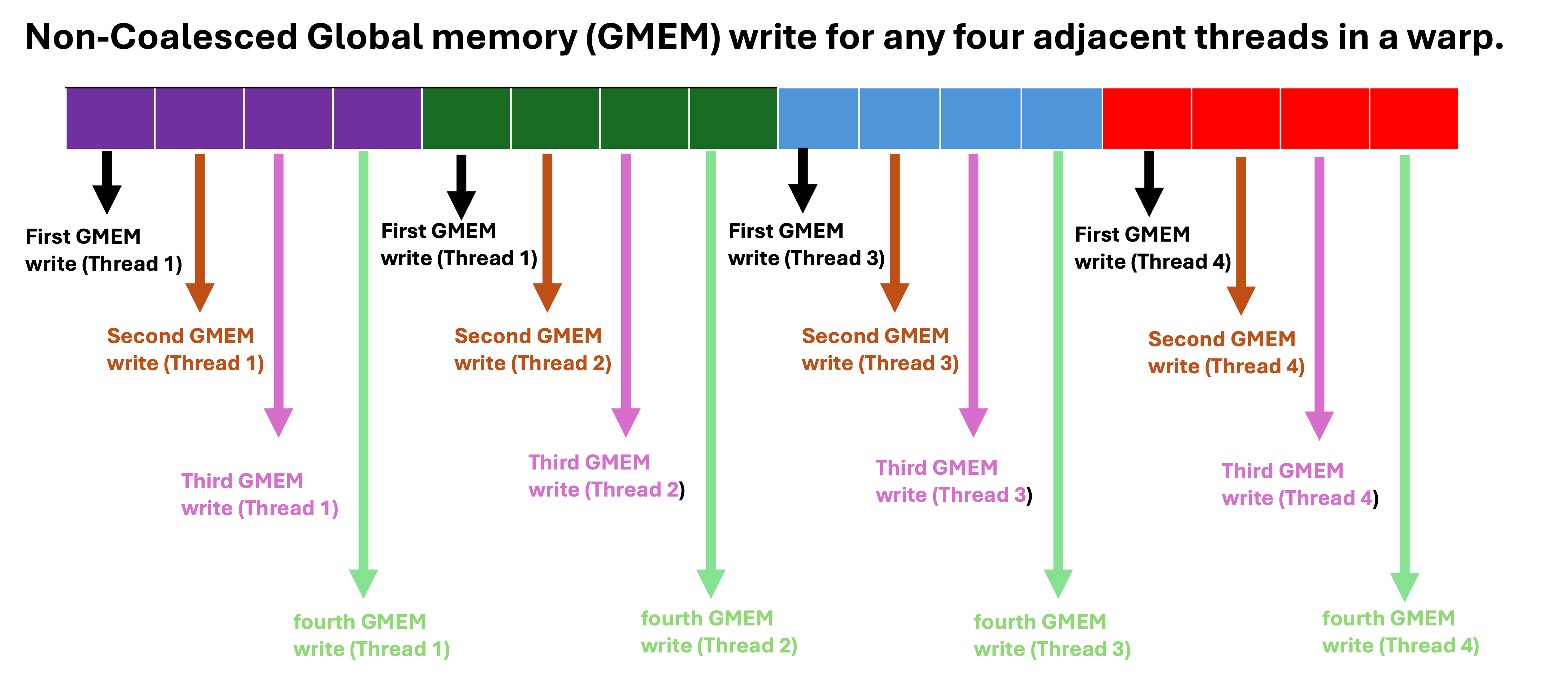
The naive implementation involves each GPU thread computing the euclidean distance between one coordinate and every other coordinate, which means each GPU thread will compute n euclidean distance out of n x n euclidean distance matrix. Therefore, each block of thread compute (n * blocksize) euclidean distance. In CUDA programming model, threads are execute by warp, which is a group of 32 threads that executes the same instruction simultaneously(Single Instruction Multiple Threads). The minimum memory transaction by a warp is 32 bytes adjacent data (also known sector), which means a warp need four coalesced 32-bytes(sector) transaction to write 32 float data type to global memory if the data are adjacent. For kernel 1, where the data written to global memory are not adjacent(coalesced), a warp will need 32 memory transaction(1024bytes) to write 32 float data type to global memory, which leads to the waste of 992 bytes of memory bandwith per warp. This is due to the row-major storage of the n x n euclidean distance matrix in GPU memory. Consequently, Nsight compute analysis shows only 4.0 bytes of the 32 bytes is utilized by each thread, which means each warp has to write to 32 different sector in order to write 32 float data type to global memory. The kernel 1 function has a compute throughput and memory throughput of 475 GFLOPS and 233 GB/s based on nsight compute. The actual memory throughput is lower when the wasted memory bandwith is considered for global memory write, in which the actual memory throughput is 207 GB/s (((3.68 + 0.73)/4.97) * 233 GB/s).
Storage of n x n euclidean distance matrix in GPU memory.
// Naive kernel function
__global__ void euclideanMatrix(LocationPrim *cordinates, float* euclideanDistance, size_t NUMDATA) {
size_t gid = blockIdx.x * blockDim.x + threadIdx.x;
if (gid < NUMDATA) {
size_t index = gid * NUMDATA;
for (int i = 0; i < NUMDATA; i++) {
float x_co = (cordinates[gid].x - cordinates[i].x);
float y_co = (cordinates[gid].y - cordinates[i].y);
float pow_xco = x_co * x_co;
float pow_yco = y_co * y_co;
float pow_plus = sqrt(pow_yco+pow_xco);
euclideanDistance[index+i] = pow_plus;
}
}
}
Nsight compute Speed of light analysis for Kernel 1.
Nsight compute memory analysis for Kernel 1.

Kernel 2: Global Memory Coalescing.
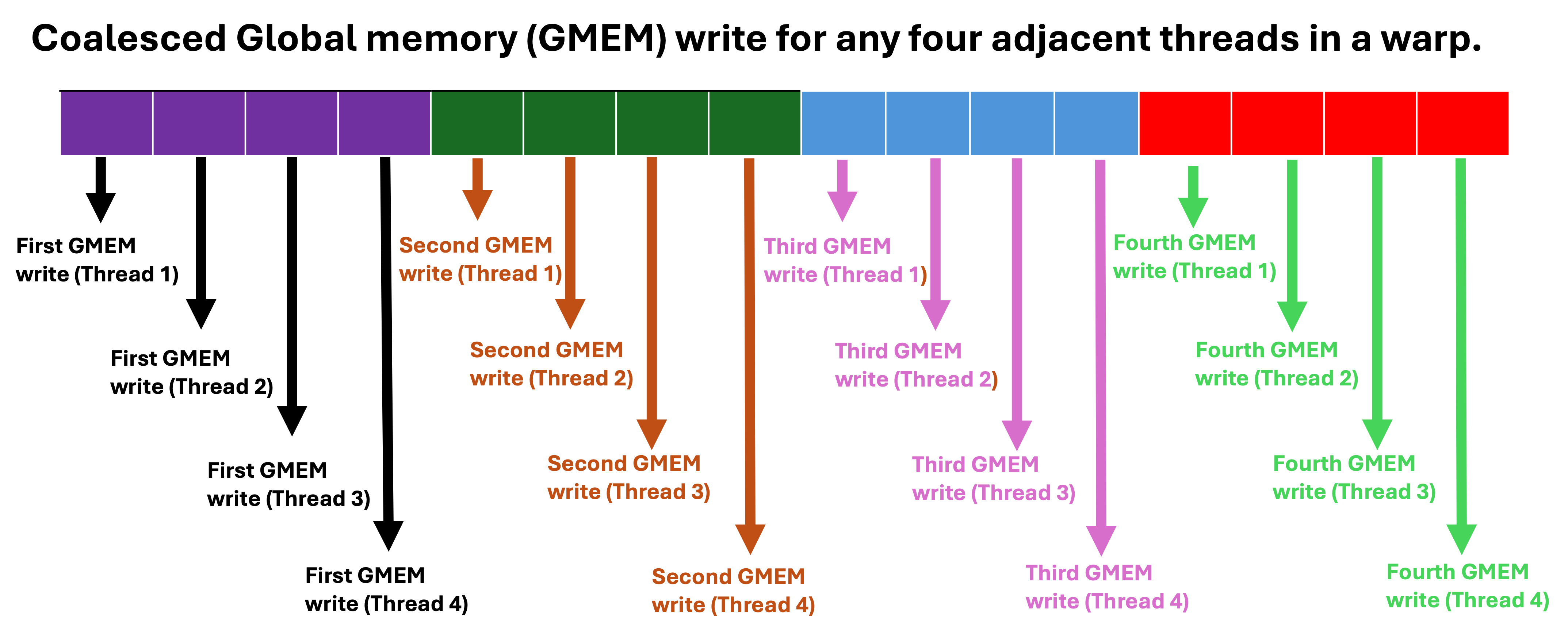
The kernel 2 function involves each warp writing the results of the euclidean distance calculations to 32 adjacent float data memory (4 adjacent sectors), which means all warps in a block writes the results of the calculations to 256 adjacent float data memory (32 adjacent sector for a blocksize of 256). The for loop condition in each thread was increased from NUMDATA to NUMDATA * blocksize, however the for loop was updated by blocksize. This allows adjacent threads to compute results that are written to adjacent float data memory. Consequently, kernel 2 function has a compute throughput and memory throughput of 993 GFLOPS and 359 GB/s, which is about 50 percent higher than that of kernel 1 function.
Non coalesced vs coalesced Global memory write.
// Kernel function with coalesced global memory write
__global__ void euclideanMatrix(LocationPrim *cordinates, float* euclideanDistance, size_t NUMDATA) {
size_t gid_start = blockIdx.x * blockDim.x;
size_t blocksize = blockDim.x * blockDim.y * blockDim.z;
size_t index;
size_t real_gid;
size_t k;
size_t j;
for (int i = threadIdx.x; i < NUMDATA * blocksize; i+=blocksize) {
j = i / NUMDATA;
real_gid = j + gid_start;
if (real_gid >= NUMDATA) {
continue;
}
k = i - (j * NUMDATA);
index = real_gid * NUMDATA;
float x_co = (cordinates[real_gid].x - cordinates[k].x);
float y_co = (cordinates[real_gid].y - cordinates[k].y);
float pow_xco = x_co * x_co;
float pow_yco = y_co * y_co;
float pow_plus = sqrt(pow_yco+pow_xco);
euclideanDistance[index+k] = pow_plus;
}
}
Nsight compute Speed of light analysis for Kernel 2.
Nsight compute memory analysis for Kernel 2.
Kernel 3: Shared Memory Cache-Blocking.
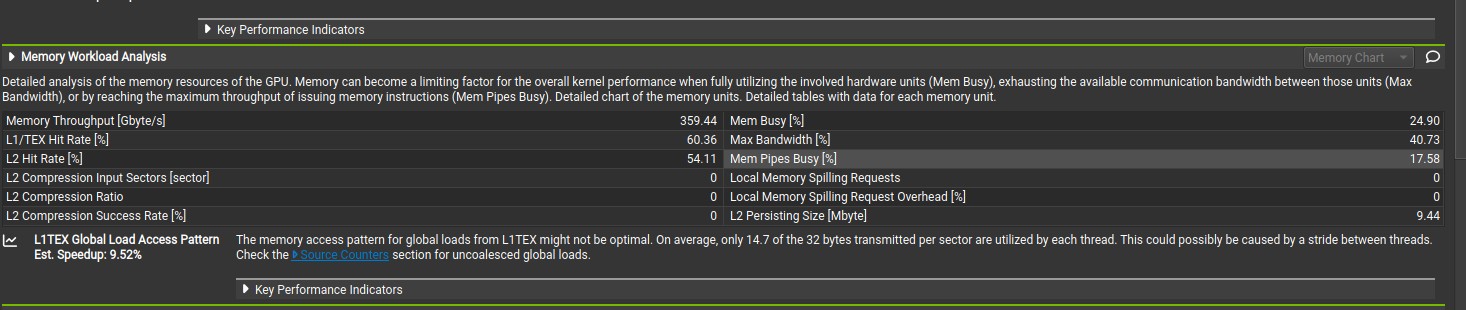
Shared memory is an on-chip memory has 100x lower latency and higher memory bandwith than uncached global memory (provided there is no bank conflict). The shared memory is used to avoid redundant transfer from global memory by different threads in a block. Shared memory also enable cooperation between threads in a block. Each thread in a block loads a chunk of the 2D coardinates points data in shared memory, after that each threads in a block uses all the data loaded in the shared memory to compute the euclidean distance. The use of shared memory increased compute throughput and memory throughput to 1520 GFLOPS and 516 GB/s based on nsight compute analysis. Additionally, the number of bytes utilized by each thread for global load increased from 14.7 bytes per sector(32 bytes) to 31.7 bytes per sector(32 bytes). The number of bytes utilized by each thread is 31.7 bytes instead of 32 bytes because the reference 2D coordinates point data is loaded twice into shared memory. Each block loads 30336 2D coordinate data points and 256 reference 2D coordinate data points, in which the 256 reference 2D coordinate point data is loaded twice because it is part of the 30336 2D coordinate data points. The total sector loaded by each block is ((30336 + 256) * 8 bytes/32 bytes) = 7648 sectors. The total sector without 256 reference 2D coordinate points is ((30336 * 8 bytes)/32 bytes) = 7584 sectors. The number of bytes per sector utilized by each thread is (7584/7648 * 32 bytes) = 31.7 bytes. This disappears when the 2D coordinate data points on the y-axis are all different from that of x-axis.
// Kernel function with shared memory
__global__ void euclideanMatrixDynamicSharedMemory(LocationPrim *cordinates, float* euclideanDistance, size_t NUMDATA,
int numDataPerThread) {
size_t gid_start = blockIdx.x * blockDim.x;
size_t gid = blockIdx.x * blockDim.x + threadIdx.x;
extern __shared__ LocationPrim locations [];
int blocksize = blockDim.x * blockDim.y * blockDim.z;
size_t numofDataperBatch = (numDataPerThread) * blocksize;
auto numBatchToFetch = [&](int batchfetched) -> int {
return ((NUMDATA - batchfetched) >= numofDataperBatch) ? numofDataperBatch : (NUMDATA - batchfetched);
};
size_t index;
size_t real_gid;
size_t t = 0;
size_t k;
size_t dataSub;
size_t ref_index;
size_t d;
size_t dataFetchSize;
size_t threadId = threadIdx.x;
size_t totalDataCompute;
if (gid < NUMDATA) {
locations[numofDataperBatch + threadId] = cordinates[gid];
}
for (int i = 0; i < NUMDATA; i+=numBatchToFetch(i)) {
dataFetchSize = numBatchToFetch(i);
for (size_t n = threadId, m = i + threadId; n < dataFetchSize; n+=blocksize, m+= blocksize) {
__pipeline_memcpy_async(&locations[n], &cordinates[m], sizeof(LocationPrim));
}
__pipeline_commit();
__pipeline_wait_prior(0);
__syncthreads();
t = 0;
totalDataCompute = dataFetchSize*blocksize;
for (size_t z = threadId, c = i + threadId; z < totalDataCompute; z+=blocksize, c+=blocksize) {
t = z/dataFetchSize;
real_gid = t + gid_start;
if (real_gid >= NUMDATA) {
continue;
}
dataSub = t * dataFetchSize;
k = c - dataSub;
index = real_gid*NUMDATA;
d = z - dataSub;
ref_index = numofDataperBatch + t;
float x_co = (locations[ref_index].x - locations[d].x);
float y_co = (locations[ref_index].y - locations[d].y);
float pow_xco = x_co * x_co;
float pow_yco = y_co * y_co;
float pow_plus = sqrt(pow_yco+pow_xco);
euclideanDistance[index+k] = pow_plus;
}
__syncthreads();
}
}
Nsight compute Speed of light analysis for Kernel 3.
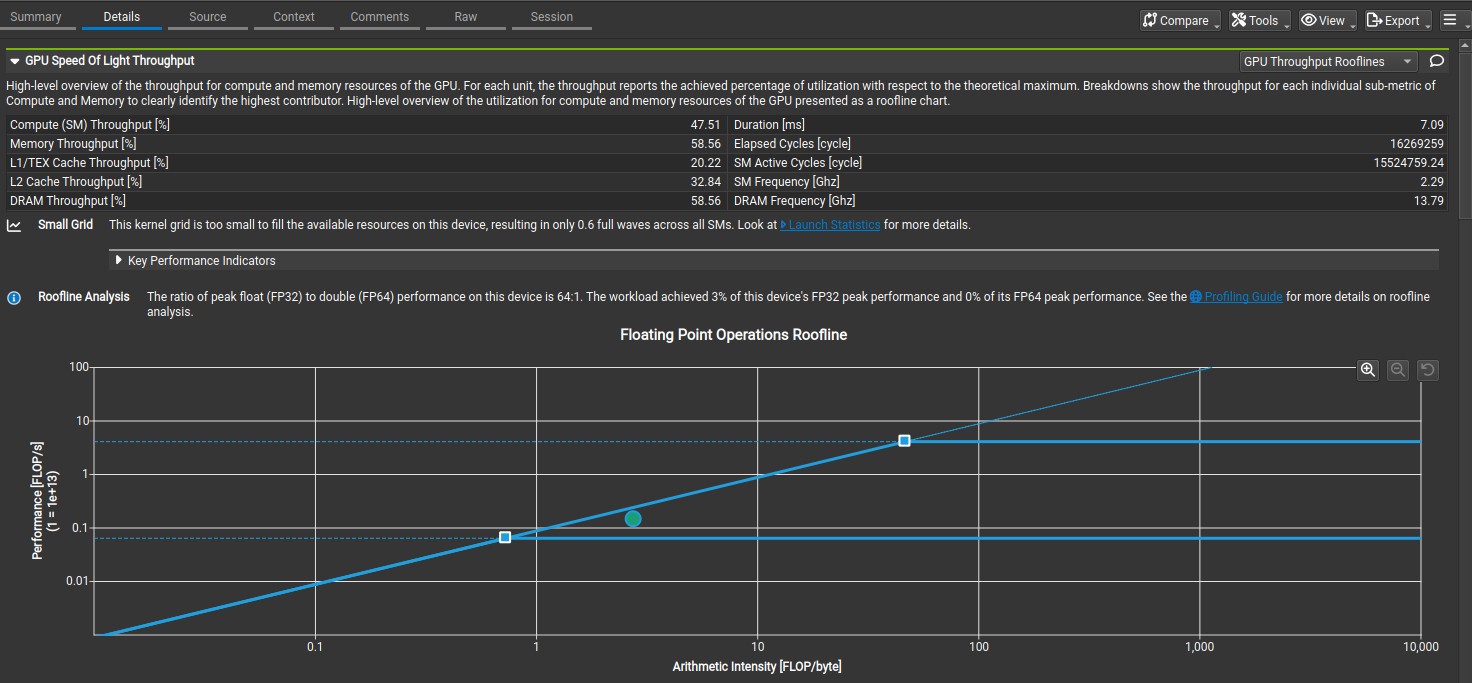
Nsight compute memory analysis for Kernel 3.

Kernel 4: Instruction Optimization.
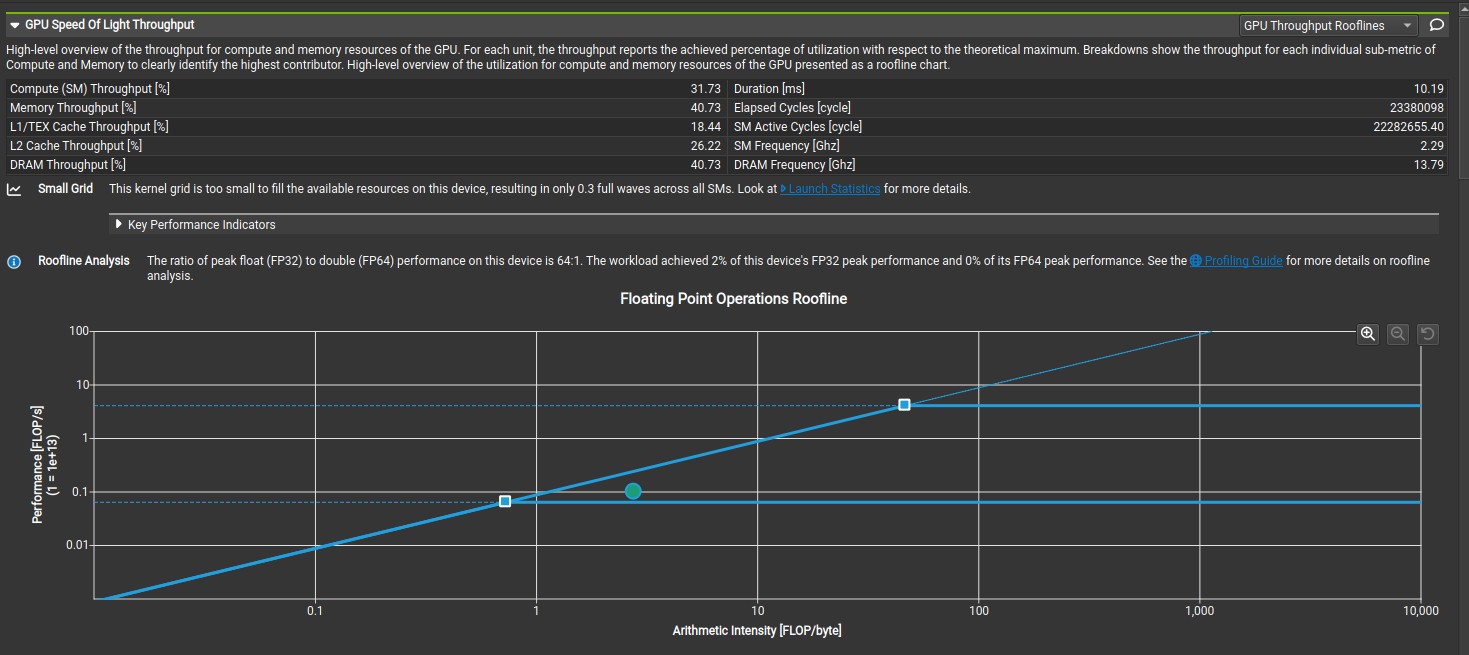
The 32-bit integer division takes significantly more clock cycle than 32-bit integer multiplication, addition and subtraction. According to CUDA C++ Best Practices Guide, Both 32-bit integer addition and 32-bit integer compare takes one clock cycle per multiprocessor while 32-bit integer multiplication takes 2 clock cycle per multiprocessor. The 32-bit integer divison was replaced with 32-bit integer addition, multiplication and compare, which increased the compute and memory throughput to 1881 GFLOPS and 681 GB/s based on nsight compute analysis. Microbenchmarking shows that the 32-bit integer division takes approximately 200 clock cycle while the combination of the 32-bit integer addition, multiplication and compare takes approximately 20 clock cycle. Considering, the number of iterations, the approximate runtime difference is ((200 - 20) * 30336)/2.4GHz = 2.28 milliseconds, which is approximately the runtime difference between kernel 3 and kernel 4 based on nsight compute analysis. This runtime difference increase linearly with number of iteration (number of 2D coordinate data points), which shows the importance of instruction optimization when scaling up an algorithm. The code for microbenchmarking is available on Github. The GPU throughput rooflines shows the memory bandwith boundary meets the peak performance boundary. Please note, the number of 2D coordinate data points should always be greater than or equal to the blocksize when using this kernel function.
// Kernel function with instruction optimization
__global__ void euclideanMatrixDynamicSharedMemory(LocationPrim *cordinates, float* euclideanDistance, size_t NUMDATA, int numDataPerThread) {
size_t gid_start = blockIdx.x * blockDim.x;
size_t gid = blockIdx.x * blockDim.x + threadIdx.x;
extern __shared__ LocationPrim locations [];
int blocksize = blockDim.x * blockDim.y * blockDim.z;
size_t numofDataperBatch = (numDataPerThread) * blocksize;
size_t numRef = ((numDataPerThread+1) * blocksize);
auto numBatchToFetch = [&](int batchfetched) -> int {
return ((NUMDATA - batchfetched) >= (numofDataperBatch + blocksize)) ? numofDataperBatch : (NUMDATA - batchfetched);
};
size_t index;
size_t real_gid;
size_t t = 0;
size_t k;
size_t dataSub;
size_t ref_index;
size_t d;
size_t dataFetchSize;
size_t threadId = threadIdx.x;
size_t totalDataCompute;
if (gid < NUMDATA) {
locations[numRef + threadId] = cordinates[gid];
}
for (int i = 0; i < NUMDATA; i+=numBatchToFetch(i)) {
dataFetchSize = numBatchToFetch(i);
for (size_t n = threadId, m = i + threadId; n < dataFetchSize; n+=blocksize, m+= blocksize) {
__pipeline_memcpy_async(&locations[n], &cordinates[m], sizeof(LocationPrim));
}
__pipeline_commit();
__pipeline_wait_prior(0);
__syncthreads();
t = 0;
totalDataCompute = dataFetchSize * blocksize;
for (size_t z = threadId, c = i + threadId; z < totalDataCompute; z+=blocksize, c+=blocksize) {
if (z >= ((t + 1) * dataFetchSize)) {
t = t + 1;
}
real_gid = t + gid_start;
if (real_gid >= NUMDATA) {
continue;
}
dataSub = t * dataFetchSize;
k = c - dataSub;
index = real_gid * NUMDATA;
d = z - dataSub;
ref_index = numRef + t;
float x_co = (locations[ref_index].x - locations[d].x);
float y_co = (locations[ref_index].y - locations[d].y);
float pow_xco = x_co * x_co;
float pow_yco = y_co * y_co;
float pow_plus = sqrt(pow_yco+pow_xco);
euclideanDistance[index+k] = pow_plus;
}
__syncthreads();
}
}
Nsight compute Speed of light analysis for Kernel 4.
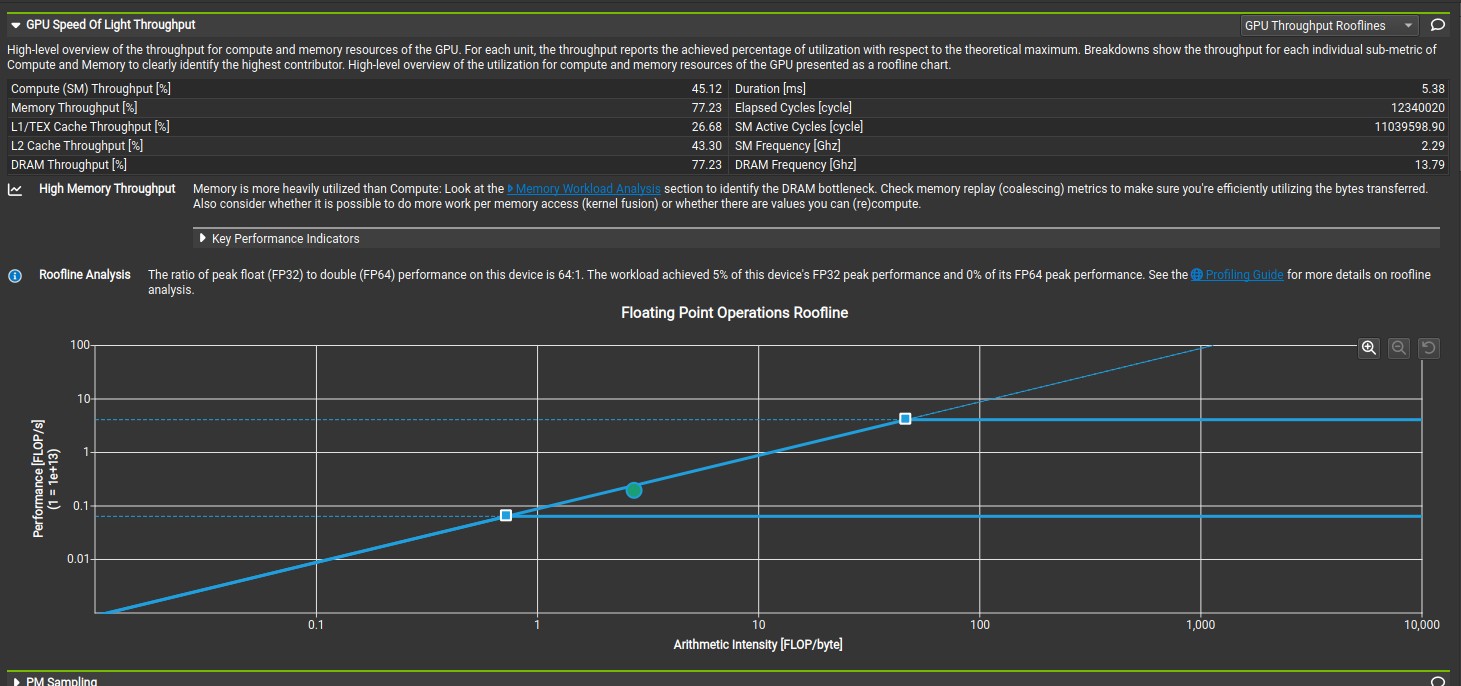
Nsight compute memory analysis for Kernel 4.

Kernel 5: Multi-Stage Asynchronous Data Copies using cuda::pipeline.
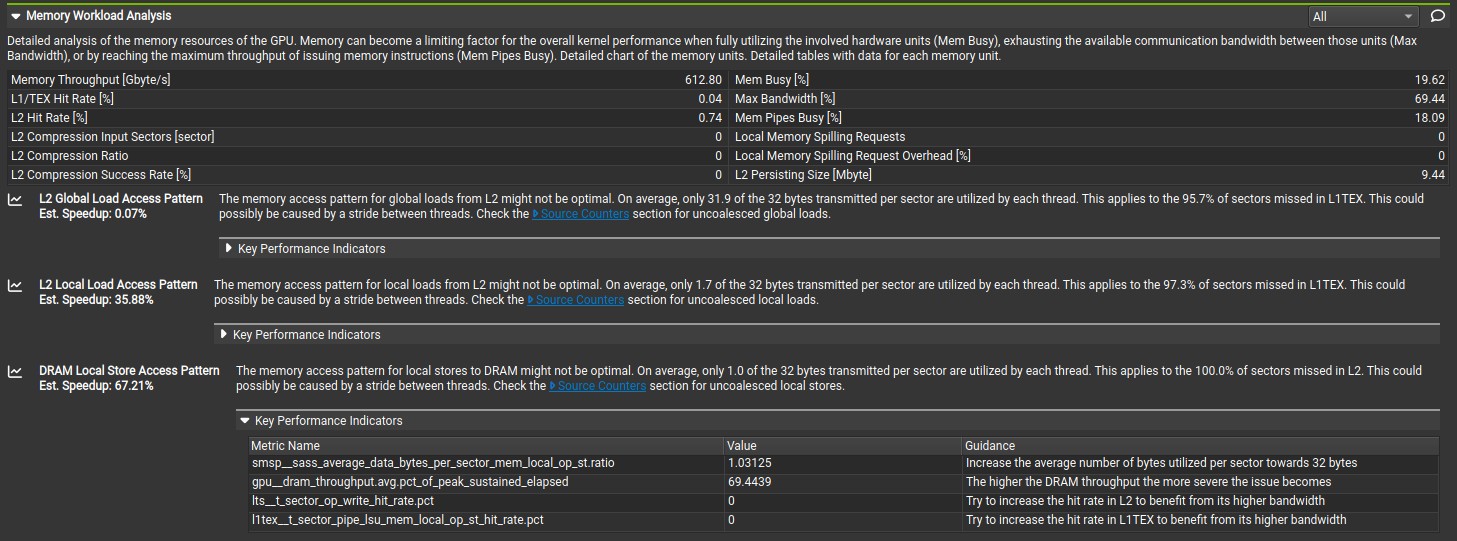
cuda::pipeline is a CUDA feature that allows overlap of computation with data movement. For kernel 5, the data movement from the global to shared memory was overlapped with the computation. However, this reduced compute and memory throughput to 1690GFLOPS and 612GB/s based on compute analysis. Additionally, the nsight compute analysis shows that the L2 local load access pattern and DRAM local store access pattern is not optimal, which means some local variable spill into L2 cache and DRAM. However, compiling the code with -Xptxas -v flag shows that there is no register spilling, which suggest that the register spilling is from the dynamic indexing of the shared_offset array.
ptxas info : 0 bytes gmem
ptxas info : Compiling entry function '_Z34euclideanMatrixDynamicSharedMemoryP12LocationPrimPfmi' for 'sm_120'
ptxas info : Function properties for _Z34euclideanMatrixDynamicSharedMemoryP12LocationPrimPfmi
16 bytes stack frame, 0 bytes spill stores, 0 bytes spill loads
ptxas info : Used 39 registers, used 1 barriers, 16 bytes cumulative stack size, 48 bytes smem
ptxas info : Compile time = 40.590 ms
/usr/bin/ld: /usr/lib/gcc/x86_64-linux-gnu/13/../../../x86_64-linux-gnu/Scrt1.o: in function `_start':
(.text+0x1b): undefined reference to `main'
collect2: error: ld returned 1 exit status
__global__ void euclideanMatrixDynamicSharedMemory(LocationPrim *cordinates, float* euclideanDistance, size_t NUMDATA, int numDataPerThread) {
size_t gid_start = blockIdx.x * blockDim.x;
size_t gid = gid_start + threadIdx.x;
extern __shared__ LocationPrim locations [];
int blocksize = blockDim.x * blockDim.y * blockDim.z;
auto grid = cooperative_groups::this_grid();
auto block = cooperative_groups::this_thread_block();
constexpr size_t stages_count = 2; // Pipeline with two stages
size_t numofDataperBatch = (numDataPerThread) * blocksize;
size_t numofDataperHalfBatch = (numDataPerThread/2) * blocksize;
size_t numRef = numofDataperBatch + blocksize;
auto numBatchToFetch = [&](int batchfetched) -> int {
return ((NUMDATA - batchfetched) >= (numofDataperHalfBatch + blocksize)) ? numofDataperHalfBatch : (NUMDATA - batchfetched);
};
size_t shared_offset[stages_count] = {0, numofDataperHalfBatch}; // Offsets to each batch
// Allocate shared storage for a two-stage cuda::pipeline:
__shared__ cuda::pipeline_shared_state<cuda::thread_scope::thread_scope_block, stages_count > shared_state;
auto pipeline = cuda::make_pipeline(block, &shared_state);
size_t firstBatchNum = numBatchToFetch(0);
pipeline.producer_acquire();
cuda::memcpy_async(block, locations + shared_offset[0], cordinates + 0, sizeof(LocationPrim)*firstBatchNum, pipeline);
pipeline.producer_commit();
size_t index;
size_t real_gid;
size_t t = 0;
size_t k;
size_t dataSub;
size_t ref_index;
size_t d;
size_t dataFetchSize;
size_t threadId = threadIdx.x;
size_t totalDataCompute;
if (gid < NUMDATA) {
//ref[threadIdx.x] = cordinates[gid];
locations[numRef + threadId] = cordinates[gid];
}
dataFetchSize = firstBatchNum;
size_t compute_stage_idx = 0;
size_t copy_stage_idx = 1;
size_t global_i = 0;
size_t current_compute_stage;
size_t nextBatchNum;
for (int i = firstBatchNum; i < NUMDATA; i+=numBatchToFetch(i)) {
nextBatchNum = numBatchToFetch(i);
//Collectively acquire the pipeline head stage from all producer threads:
pipeline.producer_acquire();
cuda::memcpy_async(block, locations + shared_offset[copy_stage_idx], cordinates + i, sizeof(LocationPrim) * nextBatchNum, pipeline);
pipeline.producer_commit();
// Collectively wait for the operations commited to the
// previous `compute` stage to complete:
pipeline.consumer_wait();
__syncthreads();
t = 0;
current_compute_stage = shared_offset[compute_stage_idx];
totalDataCompute = current_compute_stage + dataFetchSize*blocksize;
for (size_t z = current_compute_stage + threadId, c = global_i + threadId; z < totalDataCompute; z+=blocksize, c+=blocksize) {
if (z >= (current_compute_stage + (t + 1) * dataFetchSize)) {
t = t + 1;
}
real_gid = t + gid_start;
if (real_gid >= NUMDATA) {
continue;
}
dataSub = t * dataFetchSize;
k = c - dataSub;
index = real_gid*NUMDATA;
d = z - dataSub;
ref_index = numRef + t;
float x_co = (locations[ref_index].x - locations[d].x);
float y_co = (locations[ref_index].y - locations[d].y);
float pow_xco = x_co * x_co;
float pow_yco = y_co * y_co;
float pow_plus = sqrt(pow_yco+pow_xco);
euclideanDistance[index+k] = pow_plus;
}
dataFetchSize = nextBatchNum;
compute_stage_idx = (compute_stage_idx != 0) ? 0 : 1;
copy_stage_idx = (copy_stage_idx != 0) ? 0 : 1;
global_i = i;
__syncthreads();
// Collectively release the stage resources
pipeline.consumer_release();
}
// Compute the data fetch by the last iteration
pipeline.consumer_wait();
t = 0;
current_compute_stage = shared_offset[compute_stage_idx];
totalDataCompute = current_compute_stage + dataFetchSize*blocksize;
for (size_t z = current_compute_stage + threadId, c = global_i + threadId; z < totalDataCompute; z+=blocksize, c+=blocksize) {
if (z >= (current_compute_stage + (t + 1) * dataFetchSize)) {
t = t + 1;
}
real_gid = t + gid_start;
if (real_gid >= NUMDATA) {
continue;
}
dataSub = t * dataFetchSize;
k = c - dataSub;
index = real_gid*NUMDATA;
d = z - dataSub;
ref_index = numRef + t;
float x_co = (locations[ref_index].x - locations[d].x);
float y_co = (locations[ref_index].y - locations[d].y);
float pow_xco = x_co * x_co;
float pow_yco = y_co * y_co;
float pow_plus = sqrt(pow_yco+pow_xco);
euclideanDistance[index+k] = pow_plus;
}
__syncthreads();
//compute(global_out + block_batch(batch_sz-1), shared + shared_offset[(batch_sz - 1) % 2]);
pipeline.consumer_release();
}
Nsight compute Speed of light analysis for Kernel 5.
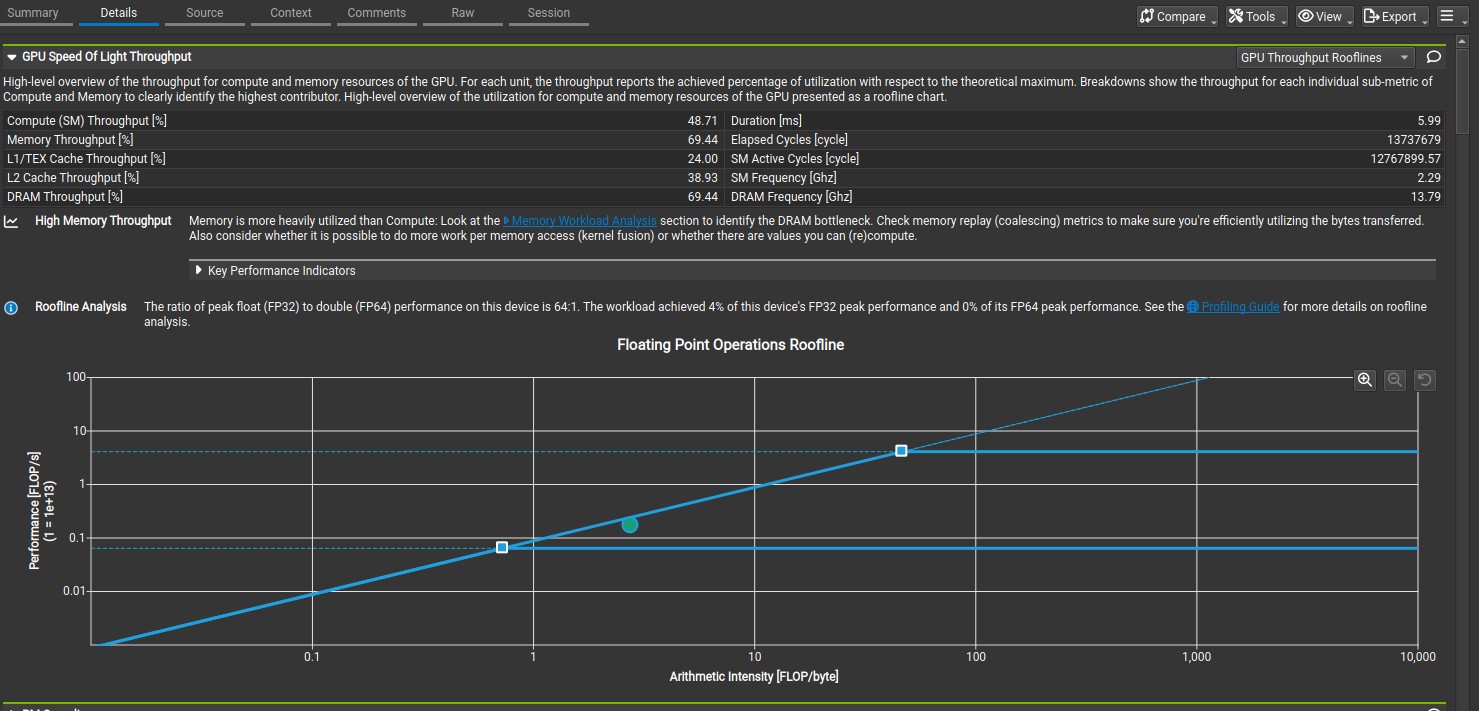
Nsight compute memory analysis for Kernel 5.
Kernel 6: Multi-Stage Asynchronous Data Copies using cuda::pipeline (optimize L2 and Global local access pattern).
The unoptimal L2 local load access pattern and DRAM local store access pattern was rectified by removing the dynamic indexing from the shared_offset array. The Dynamic indexing forces the cuda compiler to use local memory (that has higher latency than register) because the compiler does not which element will be accessed until runtime and the compiler cannot assign a register for an unknown element. According to this Nvidia blog, CUDA 13.0 supports register spilling into shared memory (that has lower latency than local memory), however it cannot be enabled here due to dynamically allocated shared memory. The register pressure was also reduced by load the reference 2D coordinate data points from the global memory directly to shared memory. This slightly increased kernel 5 compute and memory throughput to 1698GFLOPS and 615GB/s, which are still lower than that of kernel 4. Probably, there was no performance improvement from asynchronous data copies, which I will discuss in another blog post.
__global__ void euclideanMatrixDynamicSharedMemory(LocationPrim *cordinates, float* euclideanDistance, size_t NUMDATA,
int numDataPerThread) {
size_t gid_start = blockIdx.x * blockDim.x;
size_t gid = gid_start + threadIdx.x;
extern __shared__ LocationPrim locations [];
int blocksize = blockDim.x * blockDim.y * blockDim.z;
auto grid = cooperative_groups::this_grid();
auto block = cooperative_groups::this_thread_block();
constexpr size_t stages_count = 2; // Pipeline with two stages
size_t numofDataperBatch = (numDataPerThread) * blocksize;
size_t numofDataperHalfBatch = (numDataPerThread/2) * blocksize;
size_t numRef = numofDataperBatch + blocksize;
auto numBatchToFetch = [&](int batchfetched) -> int {
return ((NUMDATA - batchfetched) >= (numofDataperHalfBatch + blocksize)) ? numofDataperHalfBatch : (NUMDATA - batchfetched);
};
size_t current_compute_stage = 0;
size_t current_copy_stage = 0;
// Allocate shared storage for a two-stage cuda::pipeline:
__shared__ cuda::pipeline_shared_state<cuda::thread_scope::thread_scope_block, stages_count > shared_state;
auto pipeline = cuda::make_pipeline(block, &shared_state);
size_t firstBatchNum = numBatchToFetch(0);
size_t threadId = threadIdx.x;
if (gid < NUMDATA) {
__pipeline_memcpy_async(&locations[numRef + threadId], &cordinates[gid], sizeof(LocationPrim));
}
__pipeline_commit();
__pipeline_wait_prior(0);
pipeline.producer_acquire();
cuda::memcpy_async(block, locations + current_copy_stage, cordinates + 0, sizeof(LocationPrim)*firstBatchNum, pipeline);
pipeline.producer_commit();
size_t index;
size_t real_gid;
size_t t = 0;
size_t k;
size_t dataSub;
size_t ref_index;
size_t d;
size_t dataFetchSize;
size_t totalDataCompute;
dataFetchSize = firstBatchNum;
size_t global_i = 0;
size_t nextBatchNum;
current_copy_stage = (current_copy_stage != 0) ? 0 : numofDataperHalfBatch;
for (int i = firstBatchNum; i < NUMDATA; i+=numBatchToFetch(i)) {
nextBatchNum = numBatchToFetch(i);
//Collectively acquire the pipeline head stage from all producer threads:
pipeline.producer_acquire();
cuda::memcpy_async(block, locations + current_copy_stage, cordinates + i, sizeof(LocationPrim) * nextBatchNum, pipeline);
pipeline.producer_commit();
// Collectively wait for the operations commited to the
// previous `compute` stage to complete:
pipeline.consumer_wait();
t = 0;
//current_compute_stage = shared_offset[compute_stage_idx];
totalDataCompute = current_compute_stage + dataFetchSize*blocksize;
for (size_t z = current_compute_stage + threadId, c = global_i + threadId; z < totalDataCompute; z+=blocksize, c+=blocksize) {
if (z >= (current_compute_stage + (t + 1) * dataFetchSize)) {
t = t + 1;
}
real_gid = t + gid_start;
if (real_gid >= NUMDATA) {
continue;
}
dataSub = t * dataFetchSize;
k = c - dataSub;
index = real_gid*NUMDATA;
d = z - dataSub;
ref_index = numRef + t;
float x_co = (locations[ref_index].x - locations[d].x);
float y_co = (locations[ref_index].y - locations[d].y);
float pow_xco = x_co * x_co;
float pow_yco = y_co * y_co;
float pow_plus = sqrt(pow_yco+pow_xco);
euclideanDistance[index+k] = pow_plus;
}
dataFetchSize = nextBatchNum;
current_copy_stage = (current_copy_stage != 0) ? 0 : numofDataperHalfBatch;
current_compute_stage = (current_compute_stage != 0) ? 0 : numofDataperHalfBatch;
global_i = i;
__syncthreads();
// Collectively release the stage resources
pipeline.consumer_release();
}
// Compute the data fetch by the last iteration
pipeline.consumer_wait();
t = 0;
totalDataCompute = current_compute_stage + dataFetchSize*blocksize;
for (size_t z = current_compute_stage + threadId, c = global_i + threadId; z < totalDataCompute; z+=blocksize, c+=blocksize) {
if (z >= (current_compute_stage + (t + 1) * dataFetchSize)) {
t = t + 1;
}
real_gid = t + gid_start;
if (real_gid >= NUMDATA) {
continue;
}
dataSub = t * dataFetchSize;
k = c - dataSub;
index = real_gid*NUMDATA;
d = z - dataSub;
ref_index = numRef + t;
float x_co = (locations[ref_index].x - locations[d].x);
float y_co = (locations[ref_index].y - locations[d].y);
float pow_xco = x_co * x_co;
float pow_yco = y_co * y_co;
float pow_plus = sqrt(pow_yco+pow_xco);
euclideanDistance[index+k] = pow_plus;
}
__syncthreads();
pipeline.consumer_release();
}
Nsight compute Speed of light analysis for Kernel 6.
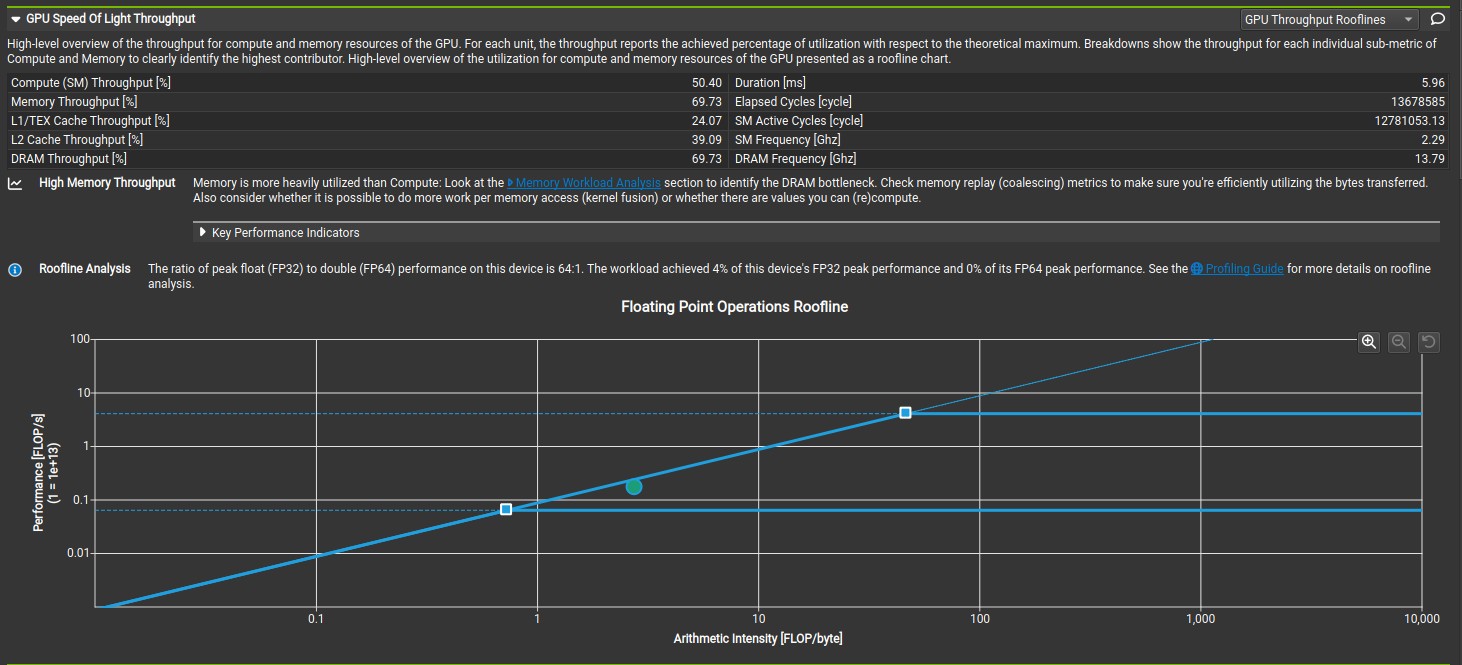
Nsight compute memory analysis for Kernel 6.

Conclusion
This technical blog discussed step by step on how to optimize kernel function for euclidean distance matrix calculation for 2D coordinate points, which kernel 4 has the best compute and memory throughput. There are more optimization opportunites by removing duplicate calculations and shared memory bank conflict(due to a struct of 8 bytes), which I will discuss later in this blog or in a different blog. All my code are available on Github.