Introduction
CUDA stream is an advanced feature of CUDA programming toolkit that allows the overlap of data transfer with kernel execution. A stream in CUDA is a command sequence issued on the device by the host code, in which the command sequence execute on device in the order it was issued by the host code. Command sequence within a stream are guaranteed to execute in the specified order but command sequence in different streams can be interleaved and, when possible, they can even run concurrently. In this technical blog post, I will discuss how to apply CUDA streams in CUDA kernel computation for the summation of 2D array along the rows. Reduction of 2D/3D array along an axis is a common computational operation in deep learning. The code used in this blog was ran on Nvidia RTX 5070 Ti.
CUDA Execution Flow
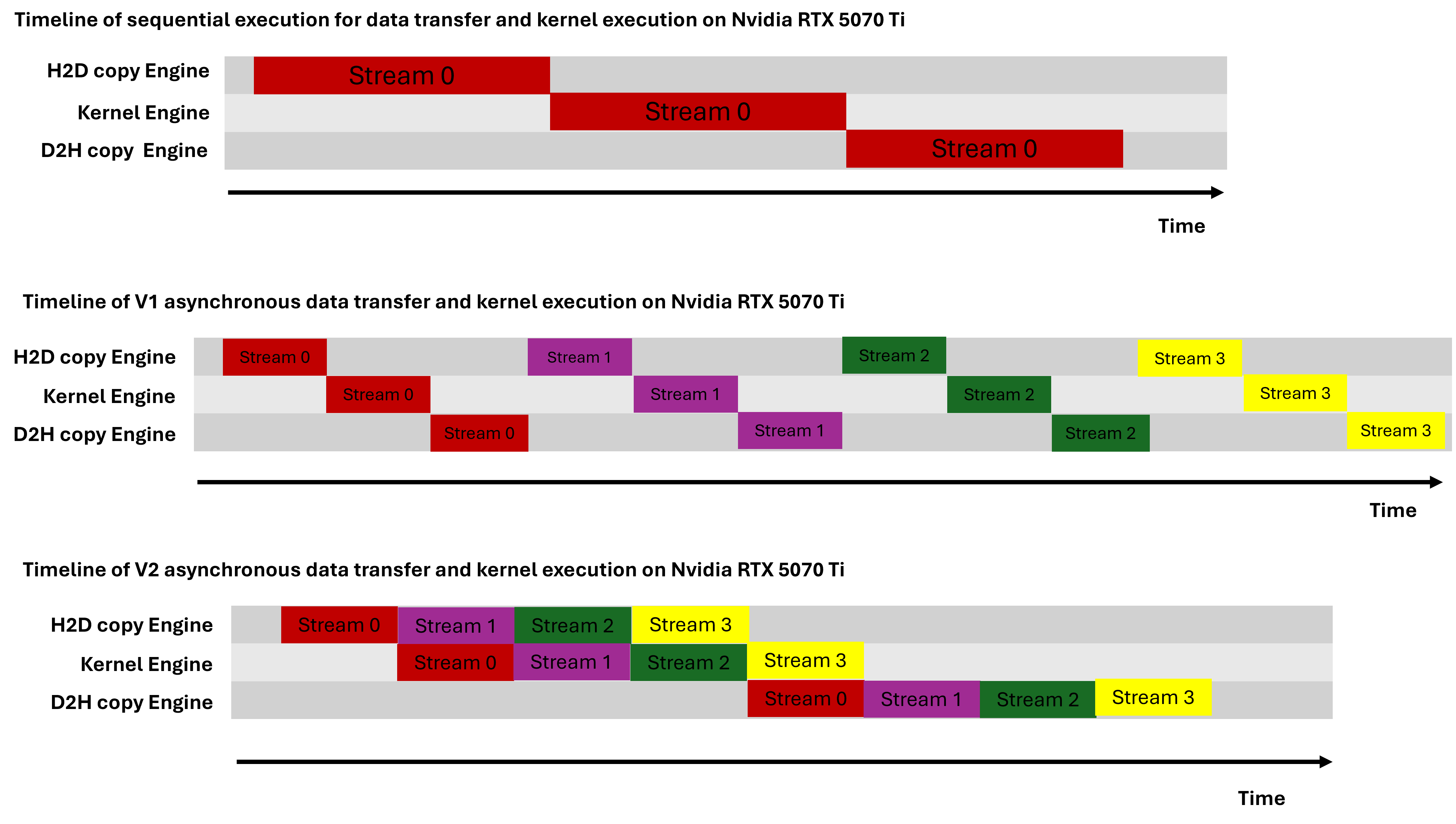
There are two CUDA execution flow, which are the serial execution flow (default stream) and concurrent execution flow (non-default stream). Figure below shows the different CUDA execution flow on NVIDIA RTX 5070 Ti. This execution flow was based on the fact that NVIDIA RTX 5070 Ti has only one copy engine, which was determined by the asyncEngineCount field of the cudaDeviceProp structure. To learn more about the different CUDA execution model, please visit Mark Harris blog post.
Execution flow for default(single) stream and non-default(mutiple) stream on Nvidia RTX 5070 Ti
Kernel function for 2D array summation along the row for default stream and non-default stream
For the default stream kernel function, each GPU thread sums all the element in the same row. Row major storage is used for the 2D array storage in GPU memory. The kernel function can also be used for 2D array summation along the column but the column major storage should be used to store the 2D array in the GPU memory and the variable nCols (number of columns) will be replaced with number of rows. The default stream kernel function will not work for the non-default stream because the kernel execution in each stream will be operate on the same section of the data. In the non-default stream, the kernel execution in different streams should operate on different section of the 2D array data. Therefore, in the kernel function for the non-default stream, the offset variable is used to calculate the section of the 2D array data for the operation by the kernel execution in the different streams. The offset variable is different for each stream, The code is available on Github repo.
// A simple CUDA kernel to reduce 2D array along the row for default(single) stream.
__global__ void reductionSumDefaultStream(int* reduceData, int* sumData, unsigned long int numData, unsigned int nCols) {
int gid = (blockIdx.x * blockDim.x + threadIdx.x);
size_t shift = (size_t)gid * (size_t) nCols;
if (gid < numData) {
int sum = 0;
for (size_t i = 0; i < nCols; i++) {
sum += reduceData[shift + i];
}
sumData[gid] = sum;
}
}
// A simple CUDA kernel to reduce 2D array along the row for non-default(multiple) stream.
__global__ void reductionSum(int* reduceData, int* sumData, unsigned long int numData, unsigned int nCols, int offset ) {
int gid = offset + (blockIdx.x * blockDim.x + threadIdx.x);
size_t shift = (size_t)gid * (size_t) nCols;
if (gid < (offset + numData)) {
int sum = 0;
for (size_t i = 0; i < nCols; i++) {
sum += reduceData[shift + i];
}
sumData[gid] = sum;
}
}
Implemention for the default stream and non-default stream.
The default stream involves data transfer from the CPU(host) memory to GPU(device) memory, kernel execution and then the result is transfered back from GPU(device) memory to CPU(host) memory. The non-default stream involves splitting the data transfered to the device memory into N batch, in which N is the number of streams. The kernel exection in each stream would operate on only one batch of the N batches of data. The number of element in each batch should be a multiple of nCols(number of columns) in order to avoid reading incorrect data from the device memory during kernel execution. Each stream will transfer the results back to the host memory. The code is available on Github repo.
// the default stream
// copy data from host memory to the device:
status = cudaMemcpy(reduceDataDev, reduceData, reduceDataSize, cudaMemcpyHostToDevice );
// checks for cuda errors
checkCudaErrors( status,"cudaMemcpy(reduceDataDev, reduceData, reduceDataSize, cudaMemcpyHostToDevice );");
// kernel launch
reductionSumDefaultStream<<< grid, threads >>>( reduceDataDev, sumDataDev, sumNumData, nCols);
status = cudaGetLastError();
// check for cuda errors
checkCudaErrors( status," reductionSum<<< grid, threads >>>( reduceDataDev, sumDataDev, numData, sumNumData); ");
// copy data from device memory to host
status = cudaMemcpy(sumData, sumDataDev, sumDataSize, cudaMemcpyDeviceToHost);
// checks for cuda errors
checkCudaErrors( status, " cudaMemcpy(sumData, sumDataDev, sumDataSize , cudaMemcpyDeviceToHost);");
// version I of the non-default stream
for (int i = 0; i < nStreams; ++i) {
unsigned long int offset = i * streamSize;
int offsetResult = i * streamSizeResult;
cudaMemcpyAsync(&reduceStrDataDev[offset], &reduceStrData[offset], streamBytes, cudaMemcpyHostToDevice, stream[i]);
reductionSum<<<grid, threads, 0, stream[i]>>>( reduceStrDataDev, sumStrDataDev, streamSizeResult, nCols, offsetResult);
cudaMemcpyAsync(&sumStrData[offsetResult], &sumStrDataDev[offsetResult], streamBytesResult, cudaMemcpyDeviceToHost, stream[i]);
}
// version II of the non-default stream
for (int i = 0; i < nStreams; ++i) {
unsigned long int offset = i * streamSize;
cudaMemcpyAsync(&reduceStrOneDataDev[offset], &reduceStrOneData[offset], streamBytes, cudaMemcpyHostToDevice, stream[i]);
}
for (int i = 0; i < nStreams; ++i) {
int offsetResult = i * streamSizeResult;
reductionSum<<<grid, threads, 0, stream[i]>>>( reduceStrOneDataDev, sumStrOneDataDev, streamSizeResult, nCols, offsetResult);
}
for (int i = 0; i < nStreams; ++i) {
int offsetResult = i * streamSizeResult;
cudaMemcpyAsync(&sumStrOneData[offsetResult], &sumStrOneDataDev[offsetResult], streamBytesResult, cudaMemcpyDeviceToHost, stream[i]);
}
Implemention for the non-default stream when all data connot fit in GPU memory at once.
The version I non-default stream implementation when all data cannot fit in GPU memory at once is the same as the implementation when the all data fit in GPU memory at once. This was due to the fact, that each stream completes all its executions on device before the next streamstart its execution. However, version II non-default stream implementation when all data cannot fit in GPU memory at once is not the same as the implementation when all data cannot fit in GPU memory at once because all streams copies all data from host to device memory before each stream start their respective kernel execution. Therefore, the version II non-default stream implementation when data fit in GPU memory would lead to memory data overwrite before kernel execution.
// version I non-default stream implementation
for (int i = 0; i < nStreams; ++i) {
unsigned long int offset = i * streamSize;
unsigned long int offsetResult = i * streamSizeResult;
cudaMemcpyAsync(&reduceStrDataDev[offset % numGPUData], &reduceStrData[offset], streamBytes, cudaMemcpyHostToDevice, stream[i]);
reductionSum<<<grid, threads, 0, stream[i]>>>( reduceStrDataDev, sumStrDataDev, streamSizeResult, nCols, offsetResult % sumGPUNumData);
cudaMemcpyAsync(&sumStrData[offsetResult ], &sumStrDataDev[offsetResult % sumGPUNumData ], streamBytesResult, cudaMemcpyDeviceToHost, stream[i]);
}
version II non-default stream implementation
for (int i = 0; i < nStreams; i+= nStreamsFitGPU) {
for (int j = 0, k = i; k < nStreams && j < nStreamsFitGPU; ++j, k++ ) {
unsigned long int offset = k * streamSize;
cudaMemcpyAsync(&reduceStrOneDataDev[offset % numGPUData], &reduceStrOneData[offset], streamBytes, cudaMemcpyHostToDevice, stream[j]);
}
for (int j = 0, k = i; k < nStreams && j < nStreamsFitGPU; ++j, k++ ) {
unsigned long int offsetResult = k * streamSizeResult;
reductionSum<<<grid, threads, 0, stream[j]>>>( reduceStrOneDataDev, sumStrOneDataDev, streamSizeResult, nCols, offsetResult % sumGPUNumData);
}
for (int j = 0, k = i; k < nStreams && j < nStreamsFitGPU; ++j, k++ ) {
unsigned long int offsetResult = k * streamSizeResult;
cudaMemcpyAsync(&sumStrOneData[offsetResult], &sumStrOneDataDev[offsetResult % sumGPUNumData ], streamBytesResult, cudaMemcpyDeviceToHost, stream[j]);
}
}
Runtime comparison.
The version II non-default implementation has the lowest runtime because it hides the kernel execution time through overlap data transfer and kernel execution. The version I non-default stream implementation has the same runtime with the default stream implemention because there is no overlap of data transfer and kernel execution.
// Runtime for default and non-default stream implementation when all data fit can in GPU memory at once
Time for sequential transfer and execute: 303.725983 milliseconds
Time for asynchronous V1 transfer and execute (ms): 299.870117 milliseconds
Time for asynchronous V2 transfer and execute (ms): 273.592133 milliseconds
// Runtime for non-default stream implementation when all data fit cannot in GPU memory at once
Time for asynchronous V1 transfer and execute (ms): 5669.757812 milliseconds
Time for asynchronous V2 transfer and execute (ms): 3936.488770 milliseconds
Conclusion.
The blog post discussed the application of CUDA streams for kernel implementation for summation of 2D array along the rows.